 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEF-PNet: Speaker Encoder-Free Personalized Speech Enhancement with Local and Global Contexts Aggregation
Paper and Code
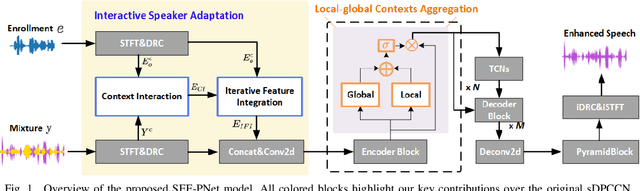
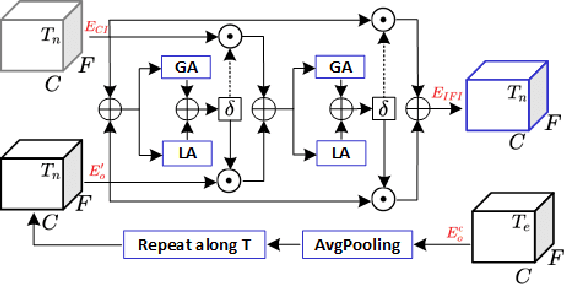
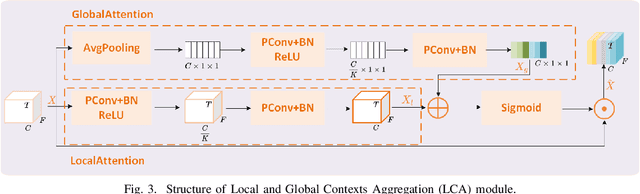
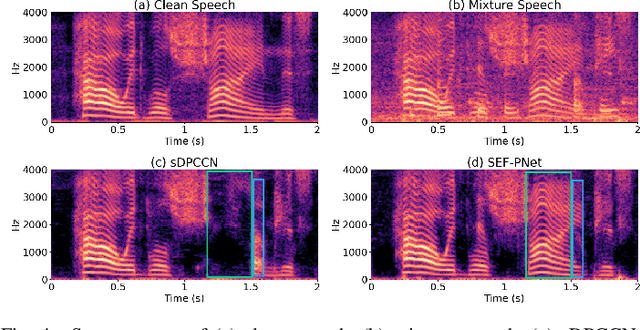
Personalized speech enhancement (PSE) methods typically rely on pre-trained speaker verification models or self-designed speaker encoders to extract target speaker clues, guiding the PSE model in isolating the desired speech. However, these approaches suffer from significant model complexity and often underutilize enrollment speaker information, limiting the potential performance of the PSE model. To address these limitations, we propose a novel Speaker Encoder-Free PSE network, termed SEF-PNet, which fully exploits the information present in both the enrollment speech and noisy mixtures. SEF-PNet incorporates two key innovations: Interactive Speaker Adaptation (ISA) and Local-Global Context Aggregation (LCA). ISA dynamically modulates the interactions between enrollment and noisy signals to enhance the speaker adaptation, while LCA employs advanced channel attention within the PSE encoder to effectively integrate local and global contextual information, thus improving feature learning. Experiments on the Libri2Mix dataset demonstrate that SEF-PNet significantly outperforms baseline models, achieving state-of-the-art PSE performance.