 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Monaural Speech Enhancement With Short-time Discrete Cosine Transform
Feb 09, 2021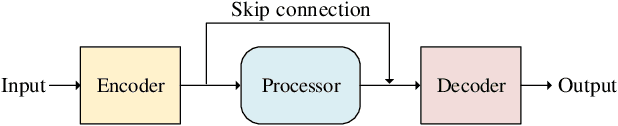

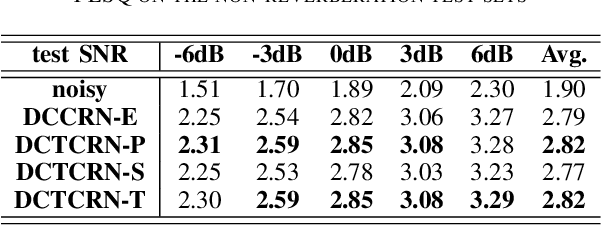
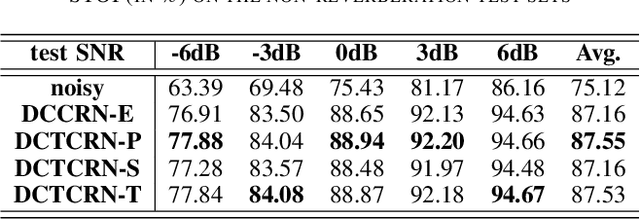
Speech enhancement algorithms based on deep learning have been improved in terms of speech intelligibility and perceptual quality greatly. Many methods focus on enhancing the amplitude spectrum while reconstructing speech using the mixture phase. Since the clean phase is very important and difficult to predict, the performance of these methods will be limited. Some researchers attempted to estimate the phase spectrum directly or indirectly, but the effect is not ideal. Recently, some studies proposed the complex-valued model and achieved state-of-the-art performance, such as deep complex convolution recurrent network (DCCRN). However, the computation of the model is huge. To reduce the complexity and further improve the performance, we propose a novel method using discrete cosine transform as the input in this paper, called deep cosine transform convolutional recurrent network (DCTCRN). Experimental results show that DCTCRN achieves state-of-the-art performance both on objective and subjective metrics. Compared with noisy mixtures, the mean opinion score (MOS) increased by 0.46 (2.86 to 3.32) absolute processed by the proposed model with only 2.86M parameters.