 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR^3: Replay, Reflection, and Ranking Rewards for LLM Reinforcement Learning
Jan 27, 2026Large reasoning models (LRMs) aim to solve diverse and complex problems through structured reasoning. Recent advances in group-based policy optimization methods have shown promise in enabling stable advantage estimation without reliance on process-level annotations. However, these methods rely on advantage gaps induced by high-quality samples within the same batch, which makes the training process fragile and inefficient when intra-group advantages collapse under challenging tasks. To address these problems, we propose a reinforcement learning mechanism named \emph{\textbf{R^3}} that along three directions: (1) a \emph{cross-context \underline{\textbf{R}}eplay} strategy that maintains the intra-group advantage by recalling valuable examples from historical trajectories of the same query, (2) an \emph{in-context self-\underline{\textbf{R}}eflection} mechanism enabling models to refine outputs by leveraging past failures, and (3) a \emph{structural entropy \underline{\textbf{R}}anking reward}, which assigns relative rewards to truncated or failed samples by ranking responses based on token-level entropy patterns, capturing both local exploration and global stability. We implement our method on Deepseek-R1-Distill-Qwen-1.5B and train it on the DeepscaleR-40k in the math domain. Experiments demonstrate our method achieves SoTA performance on several math benchmarks, representing significant improvements and fewer reasoning tokens over the base models. Code and model will be released.
Mobile-Bench-v2: A More Realistic and Comprehensive Benchmark for VLM-based Mobile Agents
May 17, 2025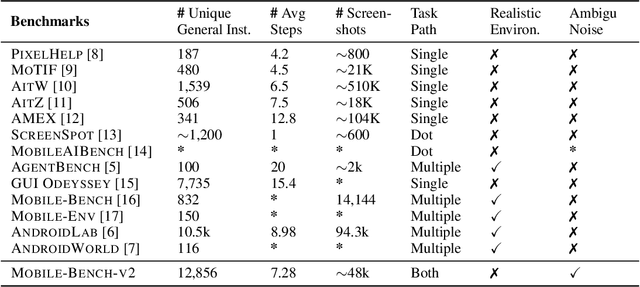
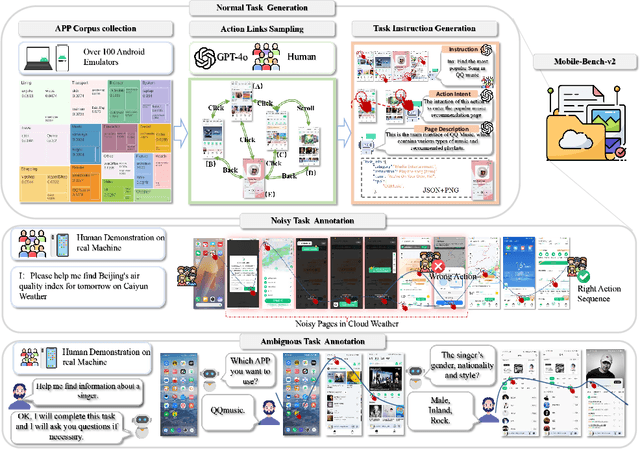
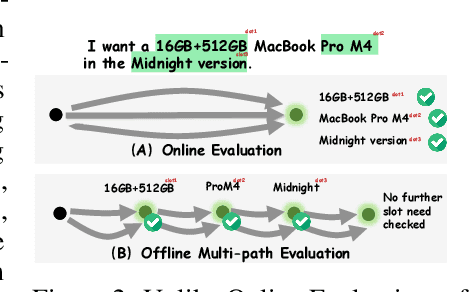
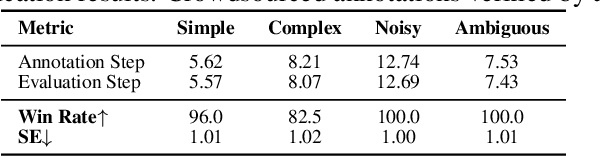
VLM-based mobile agents are increasingly popular due to their capabilities to interact with smartphone GUIs and XML-structured texts and to complete daily tasks. However, existing online benchmarks struggle with obtaining stable reward signals due to dynamic environmental changes. Offline benchmarks evaluate the agents through single-path trajectories, which stands in contrast to the inherently multi-solution characteristics of GUI tasks. Additionally, both types of benchmarks fail to assess whether mobile agents can handle noise or engage in proactive interactions due to a lack of noisy apps or overly full instructions during the evaluation process. To address these limitations, we use a slot-based instruction generation method to construct a more realistic and comprehensive benchmark named Mobile-Bench-v2. Mobile-Bench-v2 includes a common task split, with offline multi-path evaluation to assess the agent's ability to obtain step rewards during task execution. It contains a noisy split based on pop-ups and ads apps, and a contaminated split named AITZ-Noise to formulate a real noisy environment. Furthermore, an ambiguous instruction split with preset Q\&A interactions is released to evaluate the agent's proactive interaction capabilities. We conduct evaluations on these splits using the single-agent framework AppAgent-v1, the multi-agent framework Mobile-Agent-v2, as well as other mobile agents such as UI-Tars and OS-Atlas. Code and data are available at https://huggingface.co/datasets/xwk123/MobileBench-v2.
Resistance-Time Co-Modulated PointNet for Temporal Super-Resolution Simulation of Blood Vessel Flows
Nov 19, 2021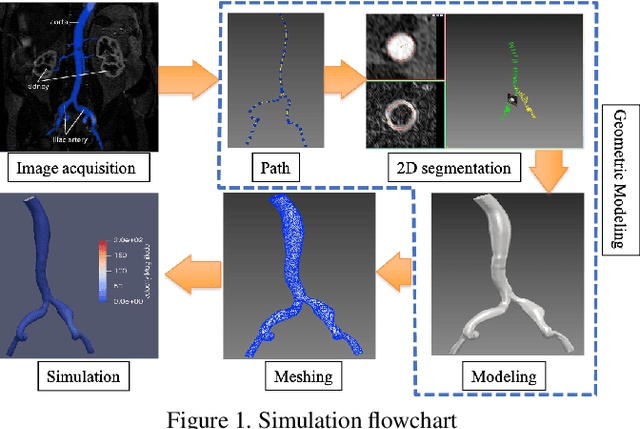
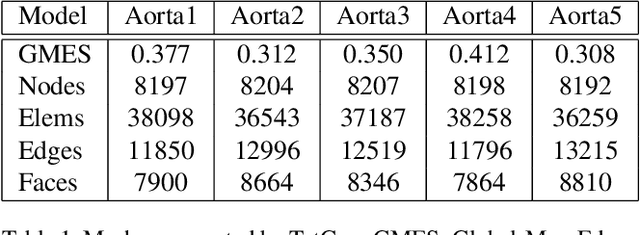
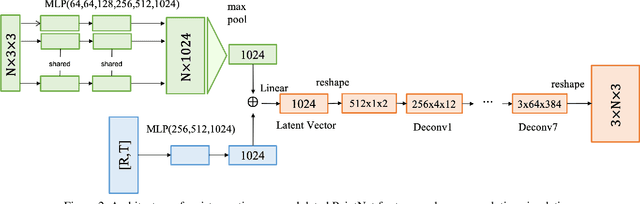
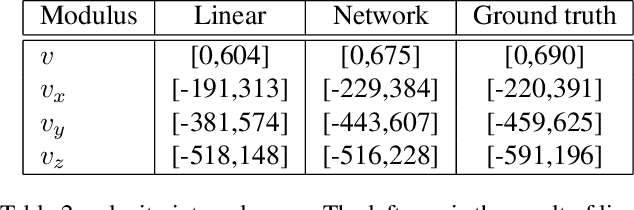
In this paper, a novel deep learning framework is proposed for temporal super-resolution simulation of blood vessel flows, in which a high-temporal-resolution time-varying blood vessel flow simulation is generated from a low-temporal-resolution flow simulation result. In our framework, point-cloud is used to represent the complex blood vessel model, resistance-time aided PointNet model is proposed for extracting the time-space features of the time-varying flow field, and finally we can reconstruct the high-accuracy and high-resolution flow field through the Decoder module. In particular, the amplitude loss and the orientation loss of the velocity are proposed from the vector characteristics of the velocity. And the combination of these two metrics constitutes the final loss function for network training. Several examples are given to illustrate the effective and efficiency of the proposed framework for temporal super-resolution simulation of blood vessel flows.