 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Guided High-Resolution Appearance Transfer via Progressive Training
Aug 27, 2020
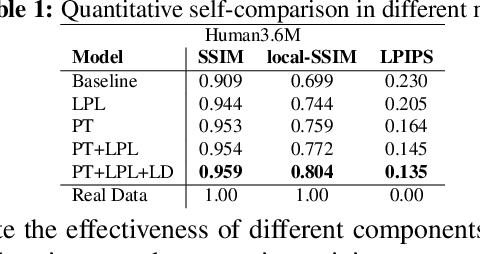
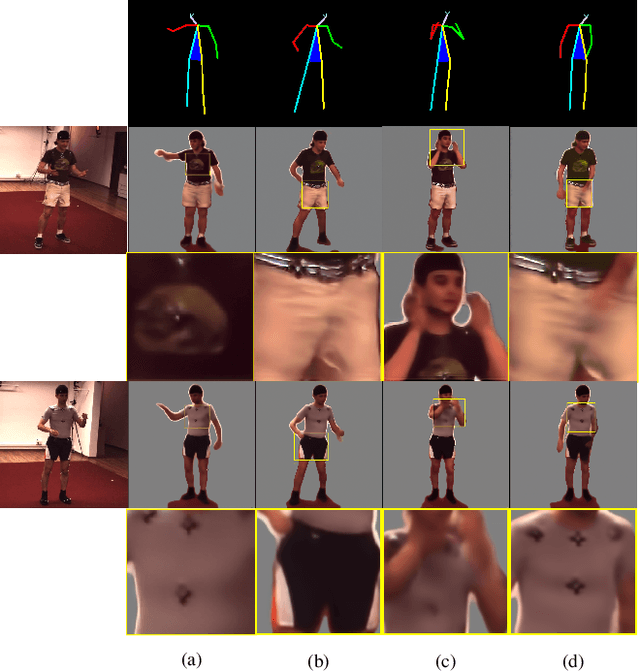
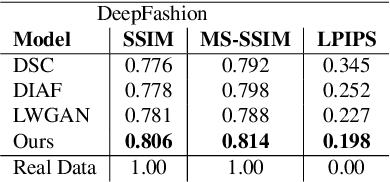
We propose a novel pose-guided appearance transfer network for transferring a given reference appearance to a target pose in unprecedented image resolution (1024 * 1024), given respectively an image of the reference and target person. No 3D model is used. Instead, our network utilizes dense local descriptors including local perceptual loss and local discriminators to refine details, which is trained progressively in a coarse-to-fine manner to produce the high-resolution output to faithfully preserve complex appearance of garment textures and geometry, while hallucinating seamlessly the transferred appearances including those with dis-occlusion. Our progressive encoder-decoder architecture can learn the reference appearance inherent in the input image at multiple scales. Extensive experimental results on the Human3.6M dataset, the DeepFashion dataset, and our dataset collected from YouTube show that our model produces high-quality images, which can be further utilized in useful applications such as garment transfer between people and pose-guided human video generation.