 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVarArray: Array-Geometry-Agnostic Continuous Speech Separation
Paper and Code
Oct 26, 2021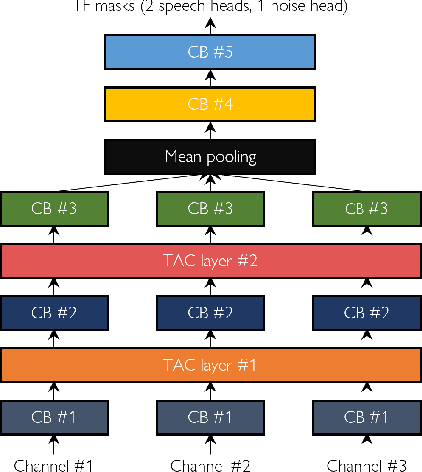
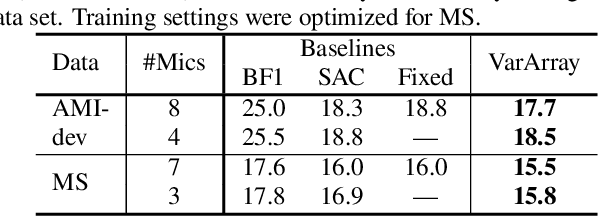
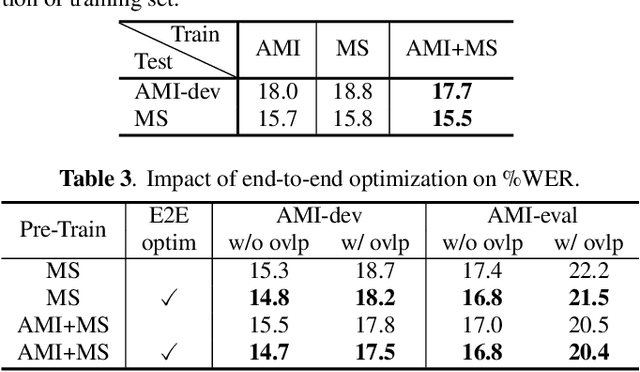
Continuous speech separation using a microphone array was shown to be promising in dealing with the speech overlap problem in natural conversation transcription. This paper proposes VarArray, an array-geometry-agnostic speech separation neural network model. The proposed model is applicable to any number of microphones without retraining while leveraging the nonlinear correlation between the input channels. The proposed method adapts different elements that were proposed before separately, including transform-average-concatenate, conformer speech separation, and inter-channel phase differences, and combines them in an efficient and cohesive way. Large-scale evaluation was performed with two real meeting transcription tasks by using a fully developed transcription system requiring no prior knowledge such as reference segmentations, which allowed us to measure the impact that the continuous speech separation system could have in realistic settings. The proposed model outperformed a previous approach to array-geometry-agnostic modeling for all of the geometry configurations considered, achieving asclite-based speaker-agnostic word error rates of 17.5% and 20.4% for the AMI development and evaluation sets, respectively, in the end-to-end setting using no ground-truth segmentations.