 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Over Quantity? LLM-Based Curation for a Data-Efficient Audio-Video Foundation Model
Mar 12, 2025Integrating audio and visual data for training multimodal foundational models remains challenging. We present Audio-Video Vector Alignment (AVVA), which aligns audiovisual (AV) scene content beyond mere temporal synchronization via a Large Language Model (LLM)-based data curation pipeline. Specifically, AVVA scores and selects high-quality training clips using Whisper (speech-based audio foundation model) for audio and DINOv2 for video within a dual-encoder contrastive learning framework. Evaluations on AudioCaps, VALOR, and VGGSound demonstrate that this approach can achieve significant accuracy gains with substantially less curated data. For instance, AVVA yields a 7.6% improvement in top-1 accuracy for audio-to-video retrieval on VGGSound compared to ImageBind, despite training on only 192 hours of carefully filtered data (vs. 5800+ hours). Moreover, an ablation study highlights that trading data quantity for data quality improves performance, yielding respective top-3 accuracy increases of 47.8, 48.4, and 58.0 percentage points on AudioCaps, VALOR, and VGGSound over uncurated baselines. While these results underscore AVVA's data efficiency, we also discuss the overhead of LLM-driven curation and how it may be scaled or approximated in larger domains. Overall, AVVA provides a viable path toward more robust, text-free audiovisual learning with improved retrieval accuracy.
Adapting Frechet Audio Distance for Generative Music Evaluation
Nov 02, 2023



The growing popularity of generative music models underlines the need for perceptually relevant, objective music quality metrics. The Frechet Audio Distance (FAD) is commonly used for this purpose even though its correlation with perceptual quality is understudied. We show that FAD performance may be hampered by sample size bias, poor choice of audio embeddings, or the use of biased or low-quality reference sets. We propose reducing sample size bias by extrapolating scores towards an infinite sample size. Through comparisons with MusicCaps labels and a listening test we identify audio embeddings and music reference sets that yield FAD scores well-correlated with acoustic and musical quality. Our results suggest that per-song FAD can be useful to identify outlier samples and predict perceptual quality for a range of music sets and generative models. Finally, we release a toolkit that allows adapting FAD for generative music evaluation.
Training Audio Captioning Models without Audio
Sep 14, 2023Automated Audio Captioning (AAC) is the task of generating natural language descriptions given an audio stream. A typical AAC system requires manually curated training data of audio segments and corresponding text caption annotations. The creation of these audio-caption pairs is costly, resulting in general data scarcity for the task. In this work, we address this major limitation and propose an approach to train AAC systems using only text. Our approach leverages the multimodal space of contrastively trained audio-text models, such as CLAP. During training, a decoder generates captions conditioned on the pretrained CLAP text encoder. During inference, the text encoder is replaced with the pretrained CLAP audio encoder. To bridge the modality gap between text and audio embeddings, we propose the use of noise injection or a learnable adapter, during training. We find that the proposed text-only framework performs competitively with state-of-the-art models trained with paired audio, showing that efficient text-to-audio transfer is possible. Finally, we showcase both stylized audio captioning and caption enrichment while training without audio or human-created text captions.
Investigations in Audio Captioning: Addressing Vocabulary Imbalance and Evaluating Suitability of Language-Centric Performance Metrics
Nov 12, 2022



The analysis, processing, and extraction of meaningful information from sounds all around us is the subject of the broader area of audio analytics. Audio captioning is a recent addition to the domain of audio analytics, a cross-modal translation task that focuses on generating natural descriptions from sound events occurring in an audio stream. In this work, we identify and improve on three main challenges in automated audio captioning: i) data scarcity, ii) imbalance or limitations in the audio captions vocabulary, and iii) the proper performance evaluation metric that can best capture both auditory and semantic characteristics. We find that generally adopted loss functions can result in an unfair vocabulary imbalance during model training. We propose two audio captioning augmentation methods that enrich the training dataset and the vocabulary size. We further underline the need for in-domain pretraining by exploring the suitability of audio encoders that were previously trained on different audio tasks. Finally, we systematically explore five performance metrics borrowed from the image captioning domain and highlight their limitations for the audio domain.
CURE Dataset: Ladder Networks for Audio Event Classification
Jan 12, 2020
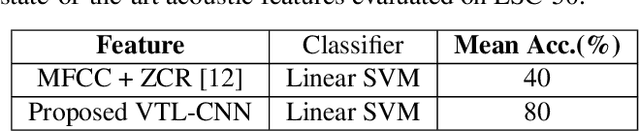
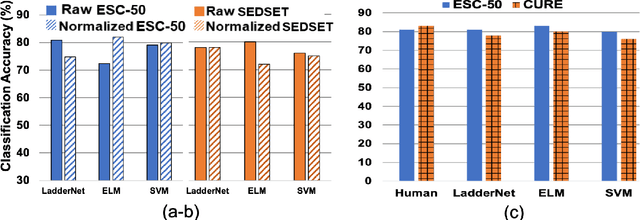
Audio event classification is an important task for several applications such as surveillance, audio, video and multimedia retrieval etc. There are approximately 3M people with hearing loss who can't perceive events happening around them. This paper establishes the CURE dataset which contains curated set of specific audio events most relevant for people with hearing loss. We propose a ladder network based audio event classifier that utilizes 5s sound recordings derived from the Freesound project. We adopted the state-of-the-art convolutional neural network (CNN) embeddings as audio features for this task. We also investigate extreme learning machine (ELM) for event classification. In this study, proposed classifiers are compared with support vector machine (SVM) baseline. We propose signal and feature normalization that aims to reduce the mismatch between different recordings scenarios. Firstly, CNN is trained on weakly labeled Audioset data. Next, the pre-trained model is adopted as feature extractor for proposed CURE corpus. We incorporate ESC-50 dataset as second evaluation set. Results and discussions validate the superiority of Ladder network over ELM and SVM classifier in terms of robustness and increased classification accuracy. While Ladder network is robust to data mismatches, simpler SVM and ELM classifiers are sensitive to such mismatches, where the proposed normalization techniques can play an important role. Experimental studies with ESC-50 and CURE corpora elucidate the differences in dataset complexity and robustness offered by proposed approaches.