 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Morphing for Audio Time Stretching
Dec 22, 2023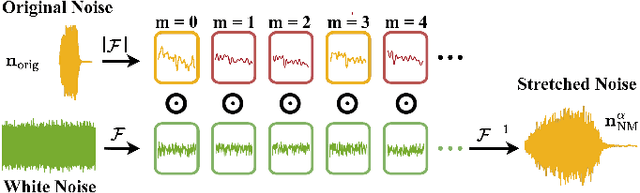
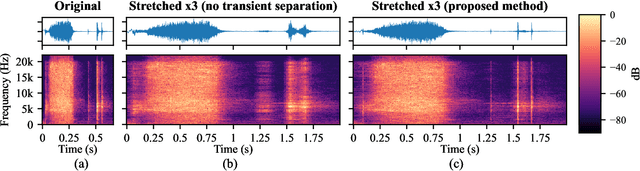
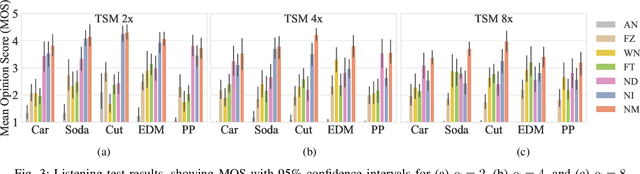

This letter introduces an innovative method to enhance the quality of audio time stretching by precisely decomposing a sound into sines, transients, and noise and by improving the processing of the latter component. While there are established methods for time-stretching sines and transients with high quality, the manipulation of noise or residual components has lacked robust solutions in prior research. The proposed method combines sound decomposition with previous techniques for audio spectral resynthesis. The time-stretched noise component is achieved by morphing its time-interpolated spectral magnitude with a white-noise excitation signal. This method stands out for its simplicity, efficiency, and audio quality. The results of a subjective experiment affirm the superiority of this approach over current state-of-the-art methods across all evaluated stretch factors. The proposed technique notably excels in extreme stretching scenarios, signifying a substantial elevation in performance. The proposed method holds promise for a wide range of applications in slow-motion media content, such as music or sports video production.
Extreme Audio Time Stretching Using Neural Synthesis
Nov 30, 2022A deep neural network solution for time-scale modification (TSM) focused on large stretching factors is proposed, targeting environmental sounds. Traditional TSM artifacts such as transient smearing, loss of presence, and phasiness are heavily accentuated and cause poor audio quality when the TSM factor is four or larger. The weakness of established TSM methods, often based on a phase vocoder structure, lies in the poor description and scaling of the transient and noise components, or nuances, of a sound. Our novel solution combines a sines-transients-noise decomposition with an independent WaveNet synthesizer to provide a better description of the noise component and an improve sound quality for large stretching factors. Results of a subjective listening test against four other TSM algorithms are reported, showing the proposed method to be often superior. The proposed method is stereo compatible and has a wide range of applications related to the slow motion of media content.
Enhanced Fuzzy Decomposition of Sound Into Sines, Transients, and Noise
Oct 25, 2022



The decomposition of sounds into sines, transients, and noise is a long-standing research problem in audio processing. The current solutions for this three-way separation detect either horizontal and vertical structures or anisotropy and orientations in the spectrogram to identify the properties of each spectral bin and classify it as sinusoidal, transient, or noise. This paper proposes an enhanced three-way decomposition method based on fuzzy logic, enabling soft masking while preserving the perfect reconstruction property. The proposed method allows each spectral bin to simultaneously belong to two classes, sine and noise or transient and noise. Results of a subjective listening test against three other techniques are reported, showing that the proposed decomposition yields a better or comparable quality. The main improvement appears in transient separation, which enjoys little or no loss of energy or leakage from the other components and performs well for test signals presenting strong transients. The audio quality of the separation is shown to depend on the complexity of the input signal for all tested methods. The proposed method helps improve the quality of various audio processing applications. A successful implementation over a state-of-the-art time-scale modification method is reported as an example.