 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll Entities are Not Created Equal: Examining the Long Tail for Fine-Grained Entity Typing
Oct 22, 2024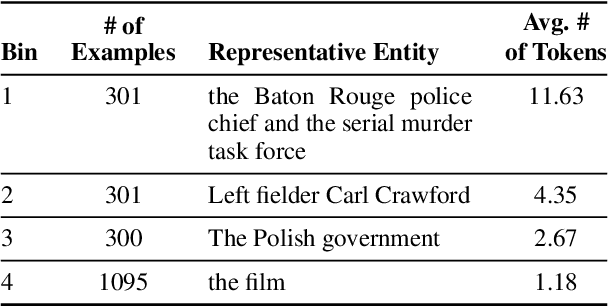
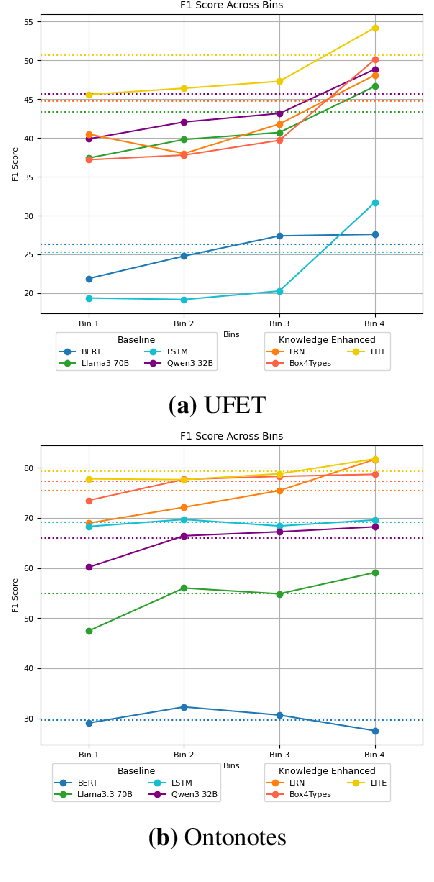
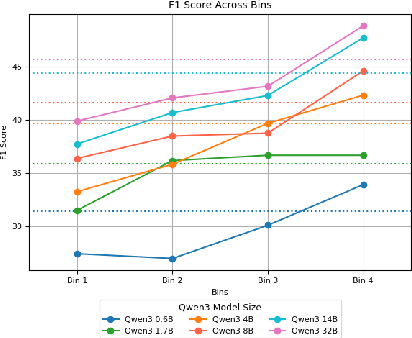
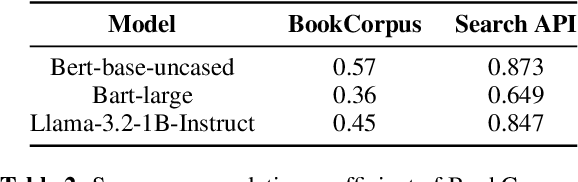
Pre-trained language models (PLMs) are trained on large amounts of data, which helps capture world knowledge alongside linguistic competence. Due to this, they are extensively used for ultra-fine entity typing tasks, where they provide the entity knowledge held in its parameter space. Given that PLMs learn from co-occurrence patterns, they likely contain more knowledge or less knowledge about entities depending on their how frequent they are in the pre-training data. In this work, we probe PLMs to elicit encoded entity probabilities and demonstrate that they highly correlate with their frequency in large-scale internet data. Then, we demonstrate that entity-typing approaches that rely on PLMs struggle with entities at the long tail on the distribution. Our findings suggests that we need to go beyond PLMs to produce solutions that perform well for rare, new or infrequent entities.