 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvoiding Resentment Via Monotonic Fairness
Sep 03, 2019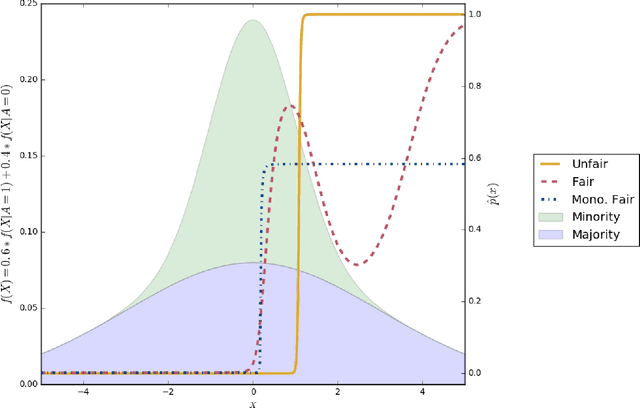
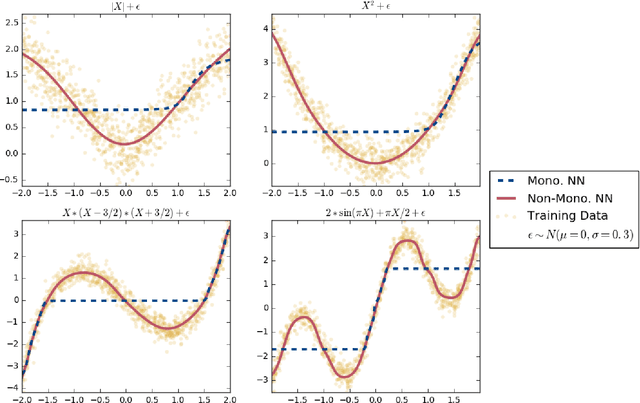
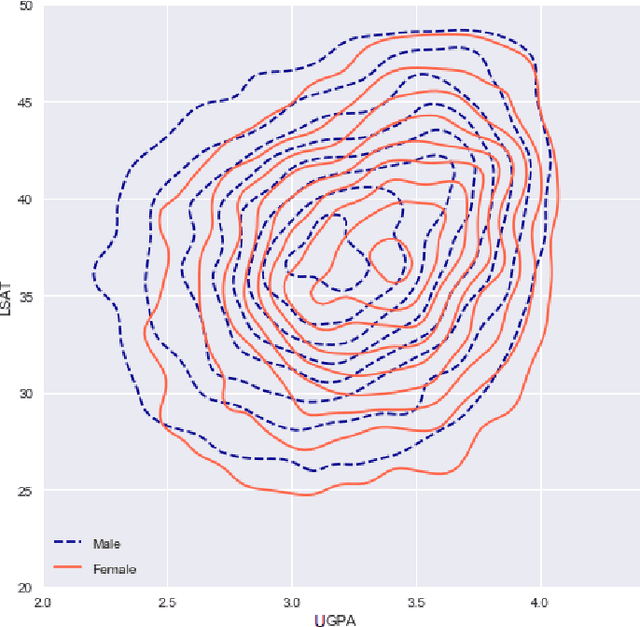
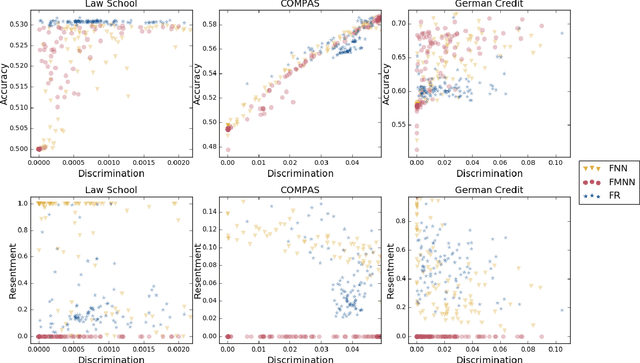
Classifiers that achieve demographic balance by explicitly using protected attributes such as race or gender are often politically or culturally controversial due to their lack of individual fairness, i.e. individuals with similar qualifications will receive different outcomes. Individually and group fair decision criteria can produce counter-intuitive results, e.g. that the optimal constrained boundary may reject intuitively better candidates due to demographic imbalance in similar candidates. Both approaches can be seen as introducing individual resentment, where some individuals would have received a better outcome if they either belonged to a different demographic class and had the same qualifications, or if they remained in the same class but had objectively worse qualifications (e.g. lower test scores). We show that both forms of resentment can be avoided by using monotonically constrained machine learning models to create individually fair, demographically balanced classifiers.
Stochastic Blockmodels with Edge Information
Apr 03, 2019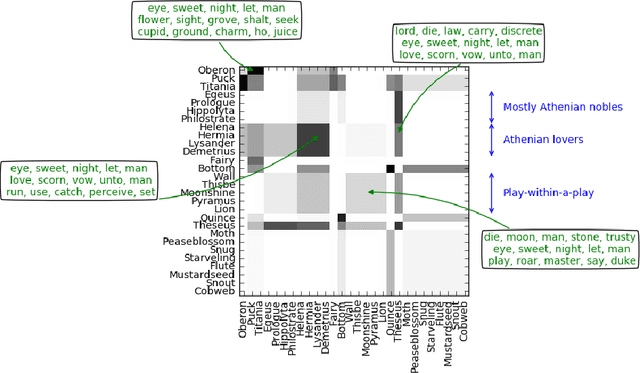
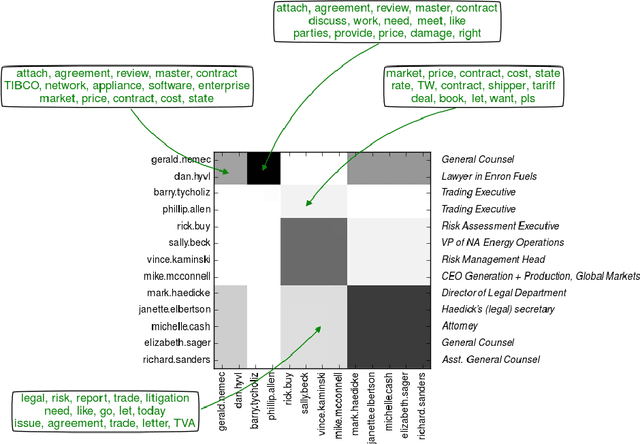


Stochastic blockmodels allow us to represent networks in terms of a latent community structure, often yielding intuitions about the underlying social structure. Typically, this structure is inferred based only on a binary network representing the presence or absence of interactions between nodes, which limits the amount of information that can be extracted from the data. In practice, many interaction networks contain much more information about the relationship between two nodes. For example, in an email network, the volume of communication between two users and the content of that communication can give us information about both the strength and the nature of their relationship. In this paper, we propose the Topic Blockmodel, a stochastic blockmodel that uses a count-based topic model to capture the interaction modalities within and between latent communities. By explicitly incorporating information sent between nodes in our network representation, we are able to address questions of interest in real-world situations, such as predicting recipients for an email message or inferring the content of an unopened email. Further, by considering topics associated with a pair of communities, we are better able to interpret the nature of each community and the manner in which it interacts with other communities.
Importance weighted generative networks
Jun 07, 2018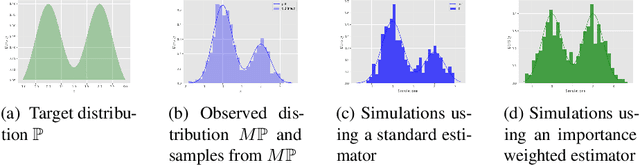

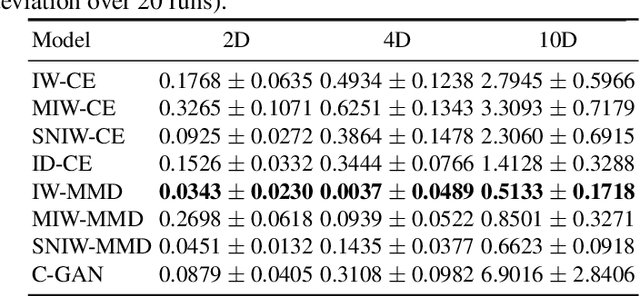
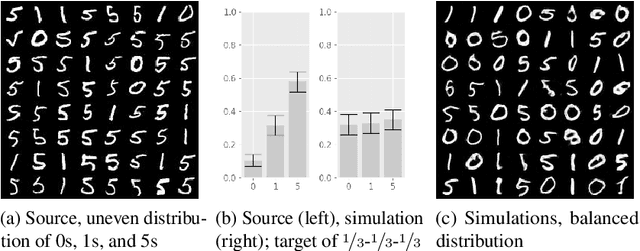
Deep generative networks can simulate from a complex target distribution, by minimizing a loss with respect to samples from that distribution. However, often we do not have direct access to our target distribution - our data may be subject to sample selection bias, or may be from a different but related distribution. We present methods based on importance weighting that can estimate the loss with respect to a target distribution, even if we cannot access that distribution directly, in a variety of settings. These estimators, which differentially weight the contribution of data to the loss function, offer both theoretical guarantees and impressive empirical performance.