 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Production Model for Retrieval-Based Chatbots
Jun 07, 2019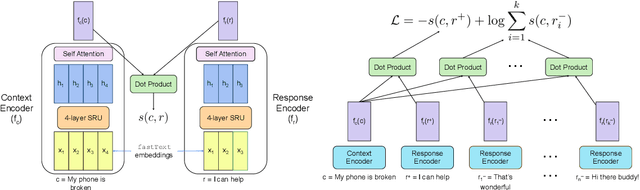
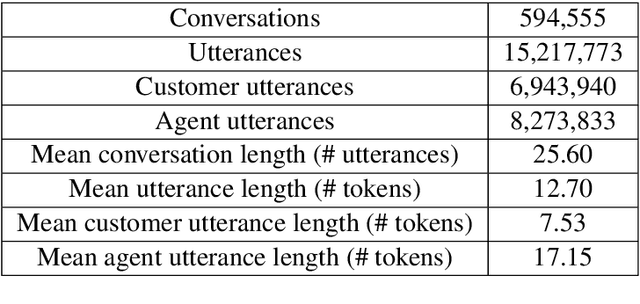


Response suggestion is an important task for building human-computer conversation systems. Recent approaches to conversation modeling have introduced new model architectures with impressive results, but relatively little attention has been paid to whether these models would be practical in a production setting. In this paper, we describe the unique challenges of building a production retrieval-based conversation system, which selects outputs from a whitelist of candidate responses. To address these challenges, we propose a dual encoder architecture which performs rapid inference and scales well with the size of the whitelist. We also introduce and compare two methods for generating whitelists, and we carry out a comprehensive analysis of the model and whitelists. Experimental results on a large, proprietary help desk chat dataset, including both offline metrics and a human evaluation, indicate production-quality performance and illustrate key lessons about conversation modeling in practice.