 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Many-To-Many Relationships for Defending Against Visual-Language Adversarial Attacks
Paper and Code
May 29, 2024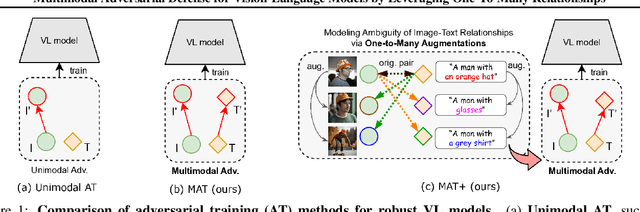
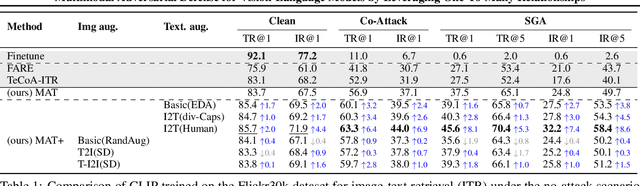
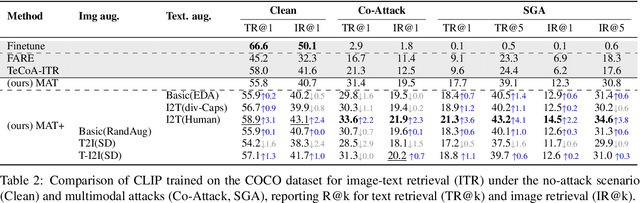
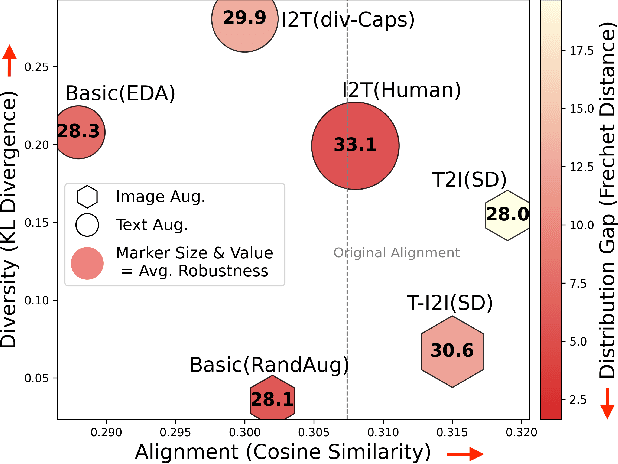
Recent studies have revealed that vision-language (VL) models are vulnerable to adversarial attacks for image-text retrieval (ITR). However, existing defense strategies for VL models primarily focus on zero-shot image classification, which do not consider the simultaneous manipulation of image and text, as well as the inherent many-to-many (N:N) nature of ITR, where a single image can be described in numerous ways, and vice versa. To this end, this paper studies defense strategies against adversarial attacks on VL models for ITR for the first time. Particularly, we focus on how to leverage the N:N relationship in ITR to enhance adversarial robustness. We found that, although adversarial training easily overfits to specific one-to-one (1:1) image-text pairs in the train data, diverse augmentation techniques to create one-to-many (1:N) / many-to-one (N:1) image-text pairs can significantly improve adversarial robustness in VL models. Additionally, we show that the alignment of the augmented image-text pairs is crucial for the effectiveness of the defense strategy, and that inappropriate augmentations can even degrade the model's performance. Based on these findings, we propose a novel defense strategy that leverages the N:N relationship in ITR, which effectively generates diverse yet highly-aligned N:N pairs using basic augmentations and generative model-based augmentations. This work provides a novel perspective on defending against adversarial attacks in VL tasks and opens up new research directions for future work.