 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Invariance Regularization in Adversarial Training to Improve Robustness-Accuracy Trade-off
Paper and Code
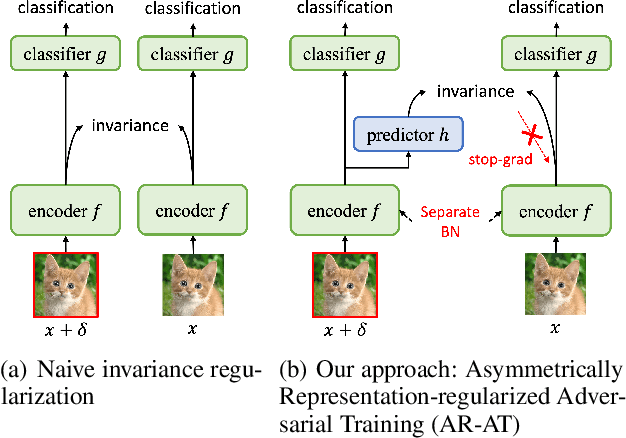

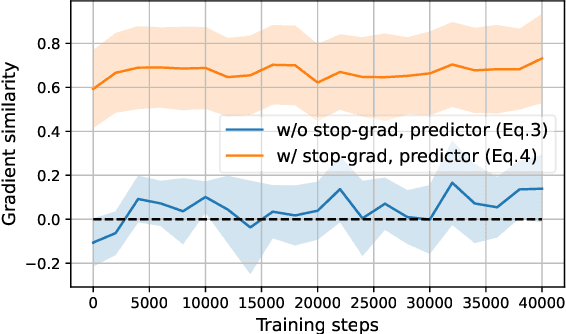
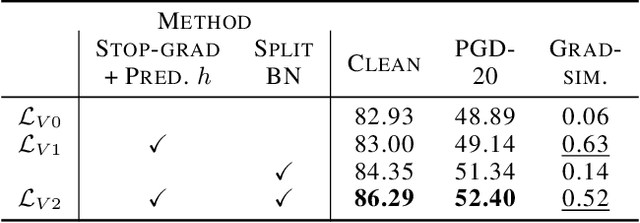
Although adversarial training has been the state-of-the-art approach to defend against adversarial examples (AEs), they suffer from a robustness-accuracy trade-off. In this work, we revisit representation-based invariance regularization to learn discriminative yet adversarially invariant representations, aiming to mitigate this trade-off. We empirically identify two key issues hindering invariance regularization: (1) a "gradient conflict" between invariance loss and classification objectives, indicating the existence of "collapsing solutions," and (2) the mixture distribution problem arising from diverged distributions of clean and adversarial inputs. To address these issues, we propose Asymmetrically Representation-regularized Adversarial Training (AR-AT), which incorporates a stop-gradient operation and a pre-dictor in the invariance loss to avoid "collapsing solutions," inspired by a recent non-contrastive self-supervised learning approach, and a split-BatchNorm (BN) structure to resolve the mixture distribution problem. Our method significantly improves the robustness-accuracy trade-off by learning adversarially invariant representations without sacrificing discriminative power. Furthermore, we discuss the relevance of our findings to knowledge-distillation-based defense methods, contributing to a deeper understanding of their relative successes.