 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestore, Assess, Repeat: A Unified Framework for Iterative Image Restoration
Mar 27, 2026Image restoration aims to recover high quality images from inputs degraded by various factors, such as adverse weather, blur, or low light. While recent studies have shown remarkable progress across individual or unified restoration tasks, they still suffer from limited generalization and inefficiency when handling unknown or composite degradations. To address these limitations, we propose RAR, a Restore, Assess and Repeat process, that integrates Image Quality Assessment (IQA) and Image Restoration (IR) into a unified framework to iteratively and efficiently achieve high quality image restoration. Specifically, we introduce a restoration process that operates entirely in the latent domain to jointly perform degradation identification, image restoration, and quality verification. The resulting model is fully trainable end to end and allows for an all-in-one assess and restore approach that dynamically adapts the restoration process. Also, the tight integration of IQA and IR into a unified model minimizes the latency and information loss that typically arises from keeping the two modules disjoint, (e.g. during image and/or text decoding). Extensive experiments show that our approach consistent improvements under single, unknown and composite degradations, thereby establishing a new state-of-the-art.
RobustVisRAG: Causality-Aware Vision-Based Retrieval-Augmented Generation under Visual Degradations
Feb 25, 2026Vision-based Retrieval-Augmented Generation (VisRAG) leverages vision-language models (VLMs) to jointly retrieve relevant visual documents and generate grounded answers based on multimodal evidence. However, existing VisRAG models degrade in performance when visual inputs suffer from distortions such as blur, noise, low light, or shadow, where semantic and degradation factors become entangled within pretrained visual encoders, leading to errors in both retrieval and generation stages. To address this limitation, we introduce RobustVisRAG, a causality-guided dual-path framework that improves VisRAG robustness while preserving efficiency and zero-shot generalization. RobustVisRAG uses a non-causal path to capture degradation signals through unidirectional attention and a causal path to learn purified semantics guided by these signals. Together with the proposed Non-Causal Distortion Modeling and Causal Semantic Alignment objectives, the framework enforces a clear separation between semantics and degradations, enabling stable retrieval and generation under challenging visual conditions. To evaluate robustness under realistic conditions, we introduce the Distortion-VisRAG dataset, a large-scale benchmark containing both synthetic and real-world degraded documents across seven domains, with 12 synthetic and 5 real distortion types that comprehensively reflect practical visual degradations. Experimental results show that RobustVisRAG improves retrieval, generation, and end-to-end performance by 7.35%, 6.35%, and 12.40%, respectively, on real-world degradations, while maintaining comparable accuracy on clean inputs.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Improving Point-based Crowd Counting and Localization Based on Auxiliary Point Guidance
May 17, 2024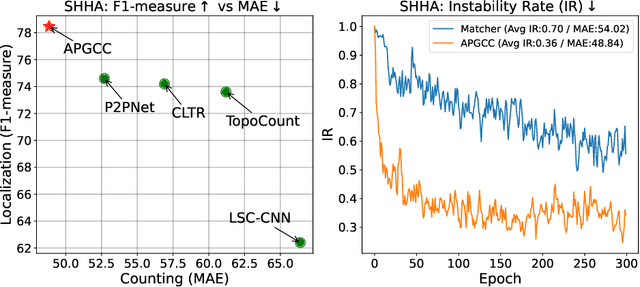
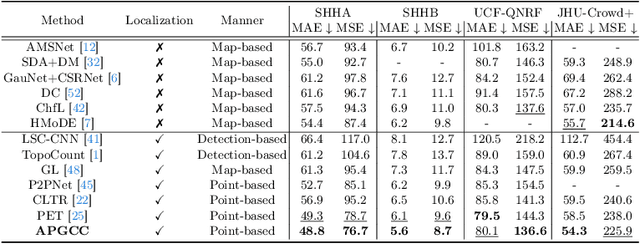
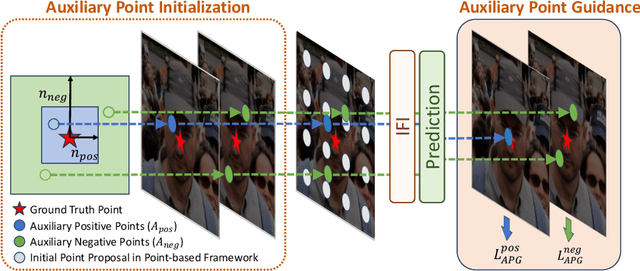
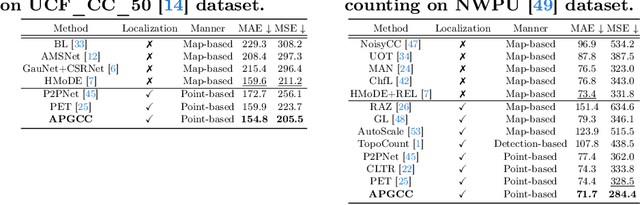
Crowd counting and localization have become increasingly important in computer vision due to their wide-ranging applications. While point-based strategies have been widely used in crowd counting methods, they face a significant challenge, i.e., the lack of an effective learning strategy to guide the matching process. This deficiency leads to instability in matching point proposals to target points, adversely affecting overall performance. To address this issue, we introduce an effective approach to stabilize the proposal-target matching in point-based methods. We propose Auxiliary Point Guidance (APG) to provide clear and effective guidance for proposal selection and optimization, addressing the core issue of matching uncertainty. Additionally, we develop Implicit Feature Interpolation (IFI) to enable adaptive feature extraction in diverse crowd scenarios, further enhancing the model's robustness and accuracy. Extensive experiments demonstrate the effectiveness of our approach, showing significant improvements in crowd counting and localization performance, particularly under challenging conditions. The source codes and trained models will be made publicly available.
RVSL: Robust Vehicle Similarity Learning in Real Hazy Scenes Based on Semi-supervised Learning
Sep 18, 2022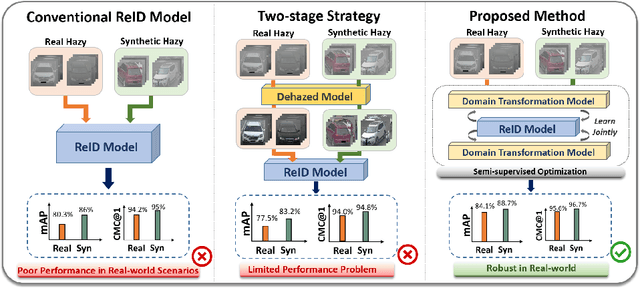

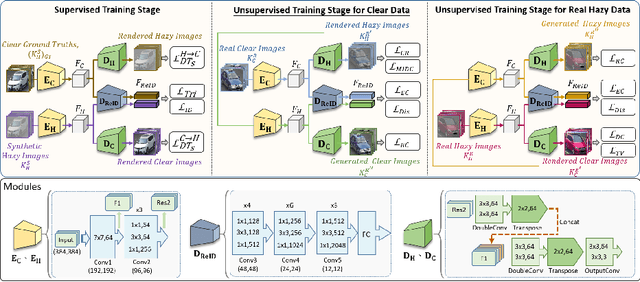

Recently, vehicle similarity learning, also called re-identification (ReID), has attracted significant attention in computer vision. Several algorithms have been developed and obtained considerable success. However, most existing methods have unpleasant performance in the hazy scenario due to poor visibility. Though some strategies are possible to resolve this problem, they still have room to be improved due to the limited performance in real-world scenarios and the lack of real-world clear ground truth. Thus, to resolve this problem, inspired by CycleGAN, we construct a training paradigm called \textbf{RVSL} which integrates ReID and domain transformation techniques. The network is trained on semi-supervised fashion and does not require to employ the ID labels and the corresponding clear ground truths to learn hazy vehicle ReID mission in the real-world haze scenes. To further constrain the unsupervised learning process effectively, several losses are developed. Experimental results on synthetic and real-world datasets indicate that the proposed method can achieve state-of-the-art performance on hazy vehicle ReID problems. It is worth mentioning that although the proposed method is trained without real-world label information, it can achieve competitive performance compared to existing supervised methods trained on complete label information.
ContourletNet: A Generalized Rain Removal Architecture Using Multi-Direction Hierarchical Representation
Nov 25, 2021


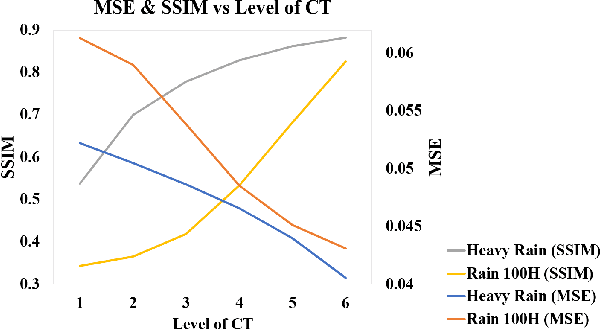
Images acquired from rainy scenes usually suffer from bad visibility which may damage the performance of computer vision applications. The rainy scenarios can be categorized into two classes: moderate rain and heavy rain scenes. Moderate rain scene mainly consists of rain streaks while heavy rain scene contains both rain streaks and the veiling effect (similar to haze). Although existing methods have achieved excellent performance on these two cases individually, it still lacks a general architecture to address both heavy rain and moderate rain scenarios effectively. In this paper, we construct a hierarchical multi-direction representation network by using the contourlet transform (CT) to address both moderate rain and heavy rain scenarios. The CT divides the image into the multi-direction subbands (MS) and the semantic subband (SS). First, the rain streak information is retrieved to the MS based on the multi-orientation property of the CT. Second, a hierarchical architecture is proposed to reconstruct the background information including damaged semantic information and the veiling effect in the SS. Last, the multi-level subband discriminator with the feedback error map is proposed. By this module, all subbands can be well optimized. This is the first architecture that can address both of the two scenarios effectively. The code is available in https://github.com/cctakaet/ContourletNet-BMVC2021.