Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting the Unseen: Detecting Hidden Backdoors in Black-Box Models
Paper and Code
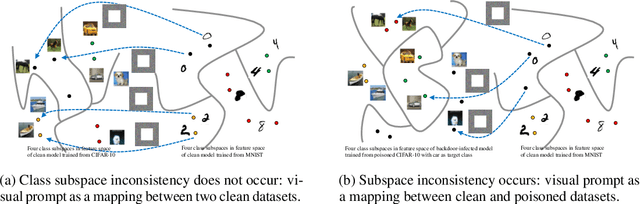

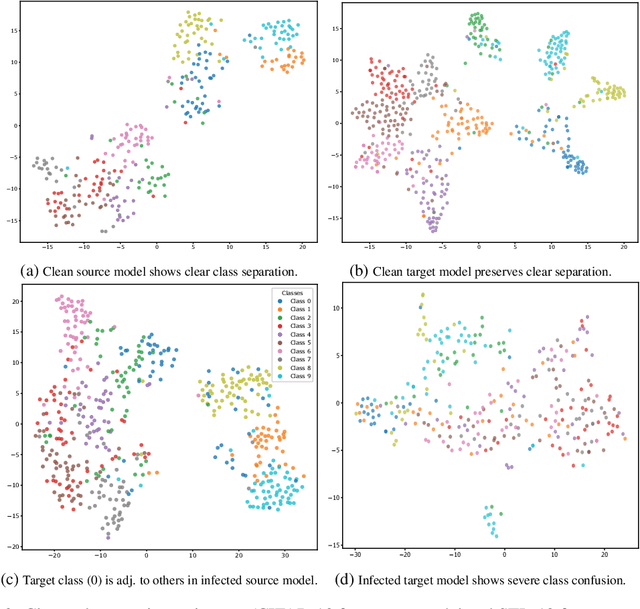
Visual prompting (VP) is a new technique that adapts well-trained frozen models for source domain tasks to target domain tasks. This study examines VP's benefits for black-box model-level backdoor detection. The visual prompt in VP maps class subspaces between source and target domains. We identify a misalignment, termed class subspace inconsistency, between clean and poisoned datasets. Based on this, we introduce \textsc{BProm}, a black-box model-level detection method to identify backdoors in suspicious models, if any. \textsc{BProm} leverages the low classification accuracy of prompted models when backdoors are present. Extensive experiments confirm \textsc{BProm}'s effectiveness.
View paper on