 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomVideo: Customizing Text-to-Video Generation with Multiple Subjects
Paper and Code
Jan 18, 2024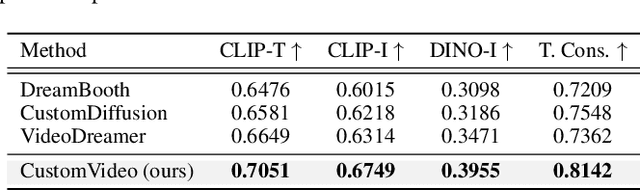
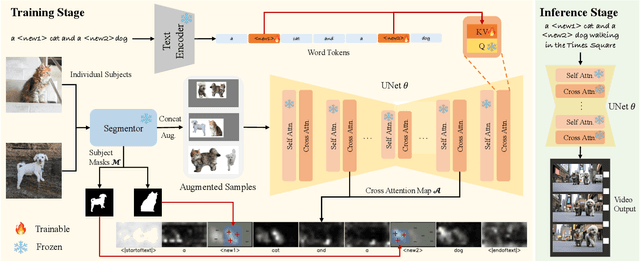
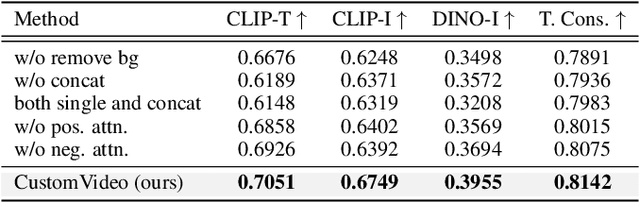

Customized text-to-video generation aims to generate high-quality videos guided by text prompts and subject references. Current approaches designed for single subjects suffer from tackling multiple subjects, which is a more challenging and practical scenario. In this work, we aim to promote multi-subject guided text-to-video customization. We propose CustomVideo, a novel framework that can generate identity-preserving videos with the guidance of multiple subjects. To be specific, firstly, we encourage the co-occurrence of multiple subjects via composing them in a single image. Further, upon a basic text-to-video diffusion model, we design a simple yet effective attention control strategy to disentangle different subjects in the latent space of diffusion model. Moreover, to help the model focus on the specific object area, we segment the object from given reference images and provide a corresponding object mask for attention learning. Also, we collect a multi-subject text-to-video generation dataset as a comprehensive benchmark, with 69 individual subjects and 57 meaningful pairs. Extensive qualitative, quantitative, and user study results demonstrate the superiority of our method, compared with the previous state-of-the-art approaches.