 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA SUPERB-Style Benchmark of Self-Supervised Speech Models for Audio Deepfake Detection
Mar 02, 2026Self-supervised learning (SSL) has transformed speech processing, with benchmarks such as SUPERB establishing fair comparisons across diverse downstream tasks. Despite it's security-critical importance, Audio deepfake detection has remained outside these efforts. In this work, we introduce Spoof-SUPERB, a benchmark for audio deepfake detection that systematically evaluates 20 SSL models spanning generative, discriminative, and spectrogram-based architectures. We evaluated these models on multiple in-domain and out-of-domain datasets. Our results reveal that large-scale discriminative models such as XLS-R, UniSpeech-SAT, and WavLM Large consistently outperform other models, benefiting from multilingual pretraining, speaker-aware objectives, and model scale. We further analyze the robustness of these models under acoustic degradations, showing that generative approaches degrade sharply, while discriminative models remain resilient. This benchmark establishes a reproducible baseline and provides practical insights into which SSL representations are most reliable for securing speech systems against audio deepfakes.
LJ-Spoof: A Generatively Varied Corpus for Audio Anti-Spoofing and Synthesis Source Tracing
Jan 12, 2026Speaker-specific anti-spoofing and synthesis-source tracing are central challenges in audio anti-spoofing. Progress has been hampered by the lack of datasets that systematically vary model architectures, synthesis pipelines, and generative parameters. To address this gap, we introduce LJ-Spoof, a speaker-specific, generatively diverse corpus that systematically varies prosody, vocoders, generative hyperparameters, bona fide prompt sources, training regimes, and neural post-processing. The corpus spans one speakers-including studio-quality recordings-30 TTS families, 500 generatively variant subsets, 10 bona fide neural-processing variants, and more than 3 million utterances. This variation-dense design enables robust speaker-conditioned anti-spoofing and fine-grained synthesis-source tracing. We further position this dataset as both a practical reference training resource and a benchmark evaluation suite for anti-spoofing and source tracing.
Multilingual Dataset Integration Strategies for Robust Audio Deepfake Detection: A SAFE Challenge System
Aug 28, 2025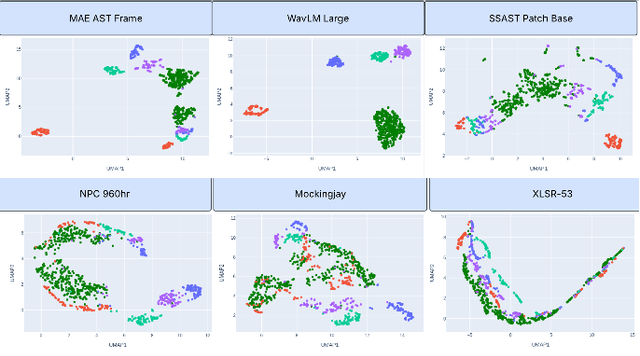
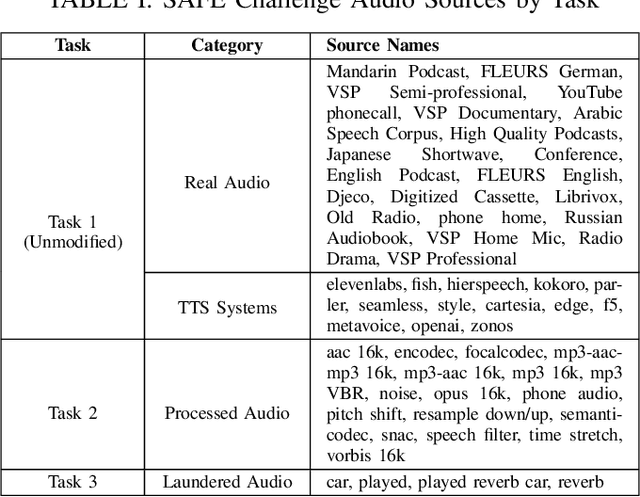
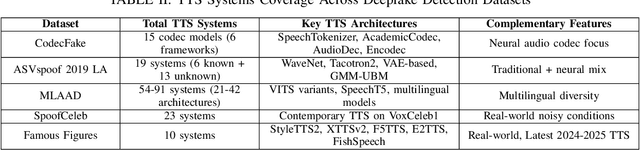
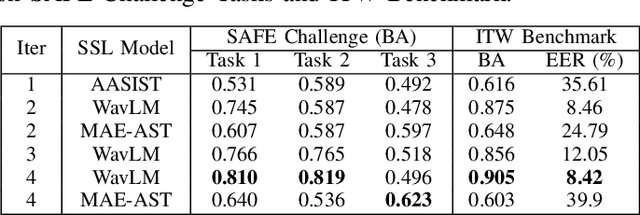
The SAFE Challenge evaluates synthetic speech detection across three tasks: unmodified audio, processed audio with compression artifacts, and laundered audio designed to evade detection. We systematically explore self-supervised learning (SSL) front-ends, training data compositions, and audio length configurations for robust deepfake detection. Our AASIST-based approach incorporates WavLM large frontend with RawBoost augmentation, trained on a multilingual dataset of 256,600 samples spanning 9 languages and over 70 TTS systems from CodecFake, MLAAD v5, SpoofCeleb, Famous Figures, and MAILABS. Through extensive experimentation with different SSL front-ends, three training data versions, and two audio lengths, we achieved second place in both Task 1 (unmodified audio detection) and Task 3 (laundered audio detection), demonstrating strong generalization and robustness.
Augmentation through Laundering Attacks for Audio Spoof Detection
Oct 01, 2024



Recent text-to-speech (TTS) developments have made voice cloning (VC) more realistic, affordable, and easily accessible. This has given rise to many potential abuses of this technology, including Joe Biden's New Hampshire deepfake robocall. Several methodologies have been proposed to detect such clones. However, these methodologies have been trained and evaluated on relatively clean databases. Recently, ASVspoof 5 Challenge introduced a new crowd-sourced database of diverse acoustic conditions including various spoofing attacks and codec conditions. This paper is our submission to the ASVspoof 5 Challenge and aims to investigate the performance of Audio Spoof Detection, trained using data augmentation through laundering attacks, on the ASVSpoof 5 database. The results demonstrate that our system performs worst on A18, A19, A20, A26, and A30 spoofing attacks and in the codec and compression conditions of C08, C09, and C10.
Is Audio Spoof Detection Robust to Laundering Attacks?
Aug 27, 2024
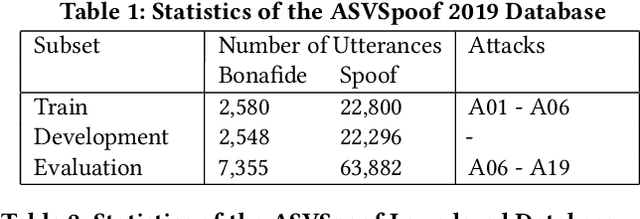

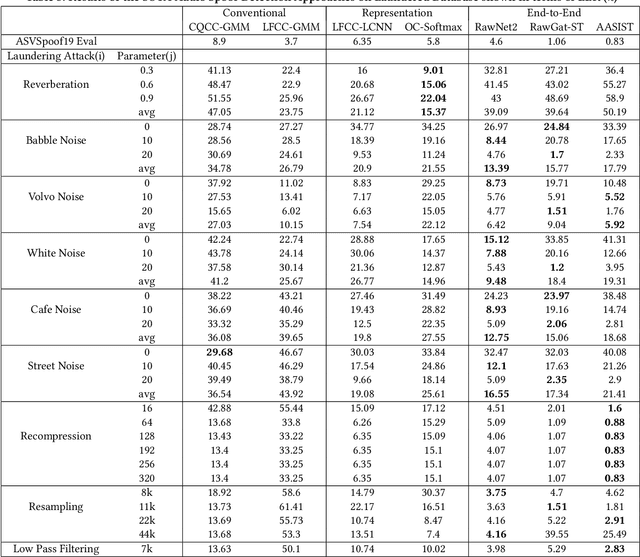
Voice-cloning (VC) systems have seen an exceptional increase in the realism of synthesized speech in recent years. The high quality of synthesized speech and the availability of low-cost VC services have given rise to many potential abuses of this technology. Several detection methodologies have been proposed over the years that can detect voice spoofs with reasonably good accuracy. However, these methodologies are mostly evaluated on clean audio databases, such as ASVSpoof 2019. This paper evaluates SOTA Audio Spoof Detection approaches in the presence of laundering attacks. In that regard, a new laundering attack database, called the ASVSpoof Laundering Database, is created. This database is based on the ASVSpoof 2019 (LA) eval database comprising a total of 1388.22 hours of audio recordings. Seven SOTA audio spoof detection approaches are evaluated on this laundered database. The results indicate that SOTA systems perform poorly in the presence of aggressive laundering attacks, especially reverberation and additive noise attacks. This suggests the need for robust audio spoof detection.
Protecting Voice-Controlled Devices against LASER Injection Attacks
Oct 13, 2023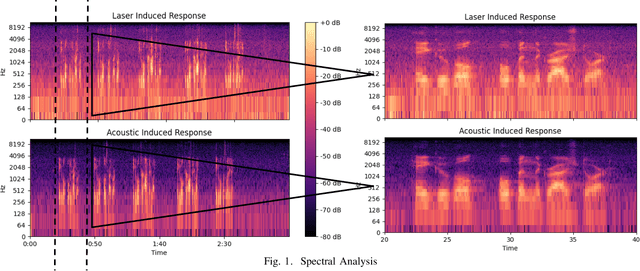
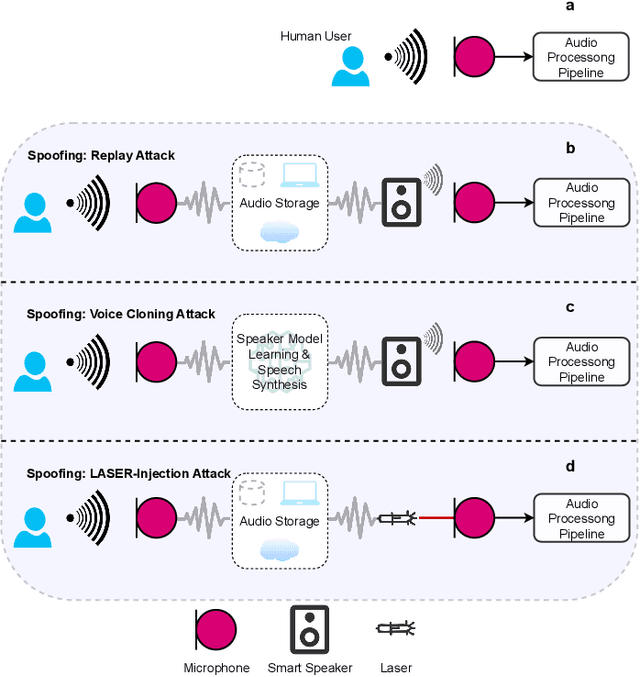
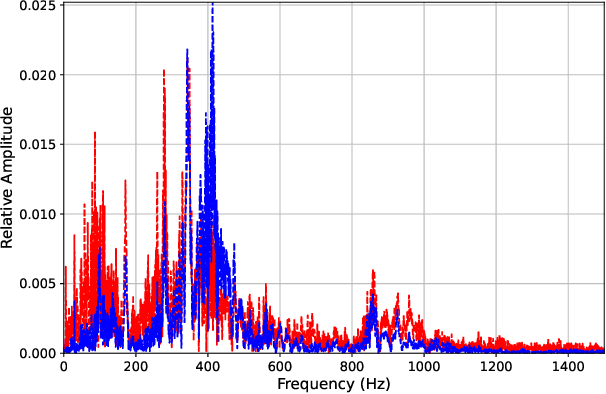
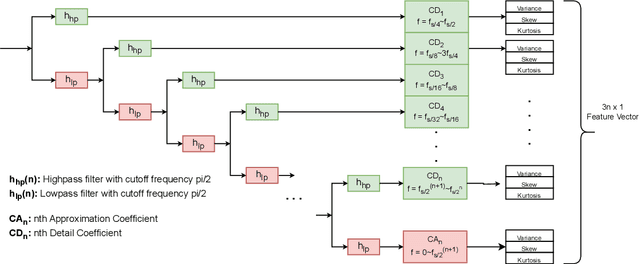
Voice-Controllable Devices (VCDs) have seen an increasing trend towards their adoption due to the small form factor of the MEMS microphones and their easy integration into modern gadgets. Recent studies have revealed that MEMS microphones are vulnerable to audio-modulated laser injection attacks. This paper aims to develop countermeasures to detect and prevent laser injection attacks on MEMS microphones. A time-frequency decomposition based on discrete wavelet transform (DWT) is employed to decompose microphone output audio signal into n + 1 frequency subbands to capture photo-acoustic related artifacts. Higher-order statistical features consisting of the first four moments of subband audio signals, e.g., variance, skew, and kurtosis are used to distinguish between acoustic and photo-acoustic responses. An SVM classifier is used to learn the underlying model that differentiates between an acoustic- and laser-induced (photo-acoustic) response in the MEMS microphone. The proposed framework is evaluated on a data set of 190 audios, consisting of 19 speakers. The experimental results indicate that the proposed framework is able to correctly classify $98\%$ of the acoustic- and laser-induced audio in a random data partition setting and $100\%$ of the audio in speaker-independent and text-independent data partition settings.
Generation of Time-Varying Impedance Attacks Against Haptic Shared Control Steering Systems
Jul 07, 2023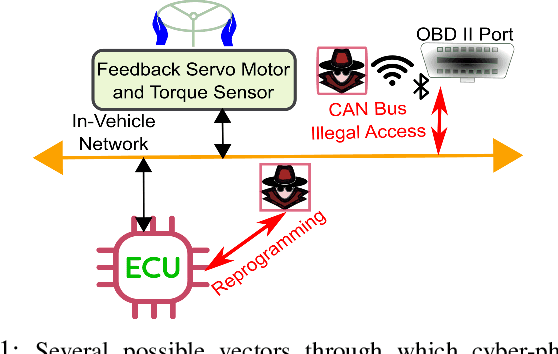


The safety-critical nature of vehicle steering is one of the main motivations for exploring the space of possible cyber-physical attacks against the steering systems of modern vehicles. This paper investigates the adversarial capabilities for destabilizing the interaction dynamics between human drivers and vehicle haptic shared control (HSC) steering systems. In contrast to the conventional robotics literature, where the main objective is to render the human-automation interaction dynamics stable by ensuring passivity, this paper takes the exact opposite route. In particular, to investigate the damaging capabilities of a successful cyber-physical attack, this paper demonstrates that an attacker who targets the HSC steering system can destabilize the interaction dynamics between the human driver and the vehicle HSC steering system through synthesis of time-varying impedance profiles. Specifically, it is shown that the adversary can utilize a properly designed non-passive and time-varying adversarial impedance target dynamics, which are fed with a linear combination of the human driver and the steering column torques. Using these target dynamics, it is possible for the adversary to generate in real-time a reference angular command for the driver input device and the directional control steering assembly of the vehicle. Furthermore, it is shown that the adversary can make the steering wheel and the vehicle steering column angular positions to follow the reference command generated by the time-varying impedance target dynamics using proper adaptive control strategies. Numerical simulations demonstrate the effectiveness of such time-varying impedance attacks, which result in a non-passive and inherently unstable interaction between the driver and the HSC steering system.
Distilling Facial Knowledge With Teacher-Tasks: Semantic-Segmentation-Features For Pose-Invariant Face-Recognition
Sep 02, 2022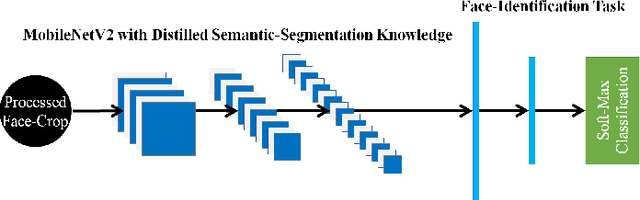
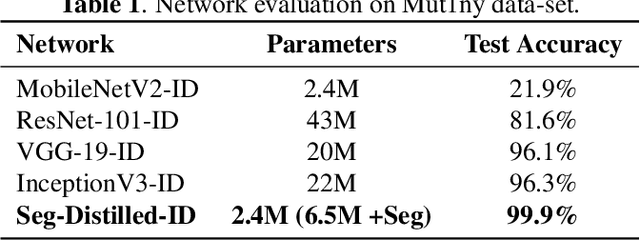
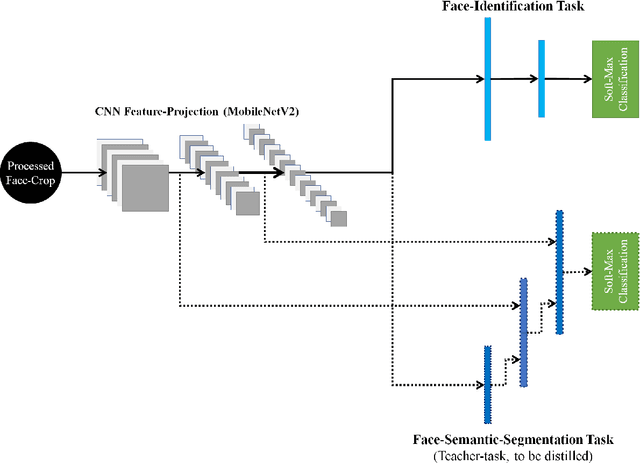

This paper demonstrates a novel approach to improve face-recognition pose-invariance using semantic-segmentation features. The proposed Seg-Distilled-ID network jointly learns identification and semantic-segmentation tasks, where the segmentation task is then "distilled" (MobileNet encoder). Performance is benchmarked against three state-of-the-art encoders on a publicly available data-set emphasizing head-pose variations. Experimental evaluations show the Seg-Distilled-ID network shows notable robustness benefits, achieving 99.9% test-accuracy in comparison to 81.6% on ResNet-101, 96.1% on VGG-19 and 96.3% on InceptionV3. This is achieved using approximately one-tenth of the top encoder's inference parameters. These results demonstrate distilling semantic-segmentation features can efficiently address face-recognition pose-invariance.
Location-aware Beamforming for MIMO-enabled UAV Communications: An Unknown Input Observer Approach
Nov 20, 2021

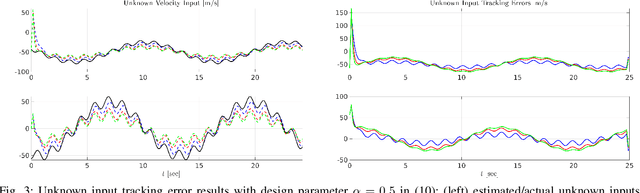
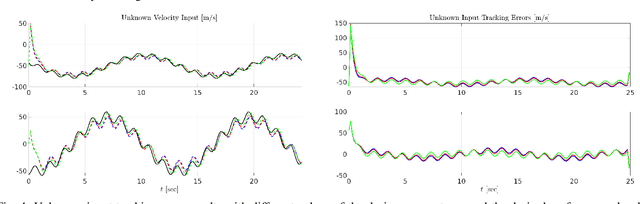
Numerous communications and networking challenges prevent deploying unmanned aerial vehicles (UAVs) in extreme environments where the existing wireless technologies are mainly ground-focused; and, as a consequence, the air-to-air channel for UAVs is not fully covered. In this paper, a novel spatial estimation for beamforming is proposed to address UAV-based joint sensing and communications (JSC). The proposed spatial estimation algorithm relies on using a delay tolerant observer-based predictor, which can accurately predict the positions of the target UAVs in the presence of uncertainties due to factors such as wind gust. The solution, which uses discrete-time unknown input observers (UIOs), reduces the joint target detection and communication complication notably by operating on the same device and performs reliably in the presence of channel blockage and interference. The effectiveness of the proposed approach is demonstrated using simulation results.
Graph-Based Intrusion Detection System for Controller Area Networks
Sep 29, 2020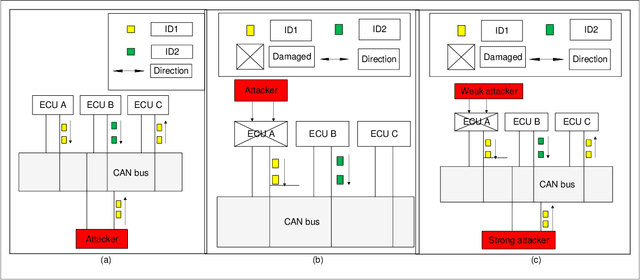
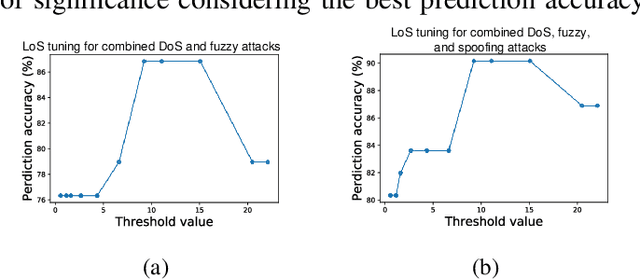
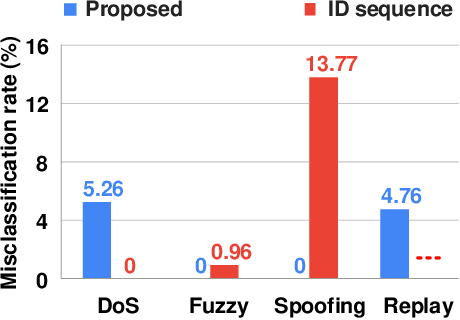
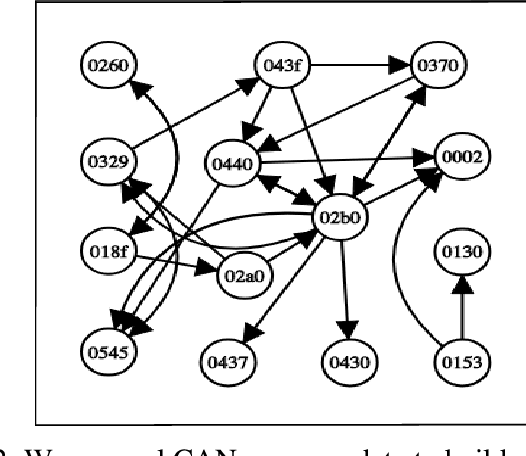
The controller area network (CAN) is the most widely used intra-vehicular communication network in the automotive industry. Because of its simplicity in design, it lacks most of the requirements needed for a security-proven communication protocol. However, a safe and secured environment is imperative for autonomous as well as connected vehicles. Therefore CAN security is considered one of the important topics in the automotive research community. In this paper, we propose a four-stage intrusion detection system that uses the chi-squared method and can detect any kind of strong and weak cyber attacks in a CAN. This work is the first-ever graph-based defense system proposed for the CAN. Our experimental results show that we have a very low 5.26% misclassification for denial of service (DoS) attack, 10% misclassification for fuzzy attack, 4.76% misclassification for replay attack, and no misclassification for spoofing attack. In addition, the proposed methodology exhibits up to 13.73% better accuracy compared to existing ID sequence-based methods.