 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Facial Knowledge With Teacher-Tasks: Semantic-Segmentation-Features For Pose-Invariant Face-Recognition
Sep 02, 2022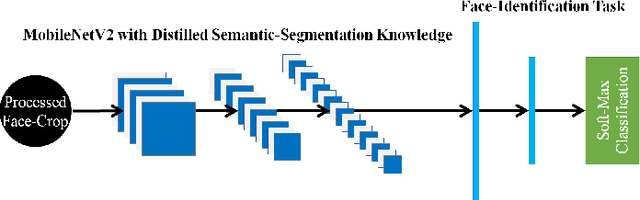
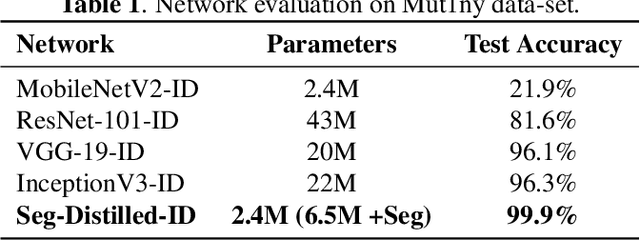
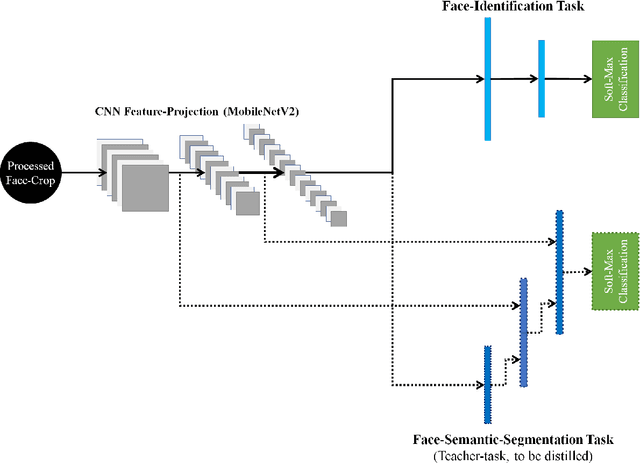

This paper demonstrates a novel approach to improve face-recognition pose-invariance using semantic-segmentation features. The proposed Seg-Distilled-ID network jointly learns identification and semantic-segmentation tasks, where the segmentation task is then "distilled" (MobileNet encoder). Performance is benchmarked against three state-of-the-art encoders on a publicly available data-set emphasizing head-pose variations. Experimental evaluations show the Seg-Distilled-ID network shows notable robustness benefits, achieving 99.9% test-accuracy in comparison to 81.6% on ResNet-101, 96.1% on VGG-19 and 96.3% on InceptionV3. This is achieved using approximately one-tenth of the top encoder's inference parameters. These results demonstrate distilling semantic-segmentation features can efficiently address face-recognition pose-invariance.