 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLJ-Spoof: A Generatively Varied Corpus for Audio Anti-Spoofing and Synthesis Source Tracing
Jan 12, 2026Speaker-specific anti-spoofing and synthesis-source tracing are central challenges in audio anti-spoofing. Progress has been hampered by the lack of datasets that systematically vary model architectures, synthesis pipelines, and generative parameters. To address this gap, we introduce LJ-Spoof, a speaker-specific, generatively diverse corpus that systematically varies prosody, vocoders, generative hyperparameters, bona fide prompt sources, training regimes, and neural post-processing. The corpus spans one speakers-including studio-quality recordings-30 TTS families, 500 generatively variant subsets, 10 bona fide neural-processing variants, and more than 3 million utterances. This variation-dense design enables robust speaker-conditioned anti-spoofing and fine-grained synthesis-source tracing. We further position this dataset as both a practical reference training resource and a benchmark evaluation suite for anti-spoofing and source tracing.
Multilingual Dataset Integration Strategies for Robust Audio Deepfake Detection: A SAFE Challenge System
Aug 28, 2025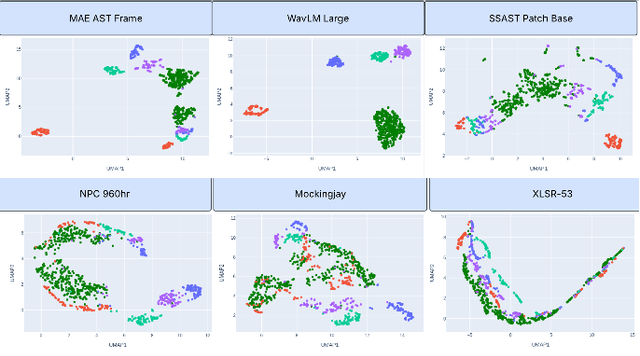
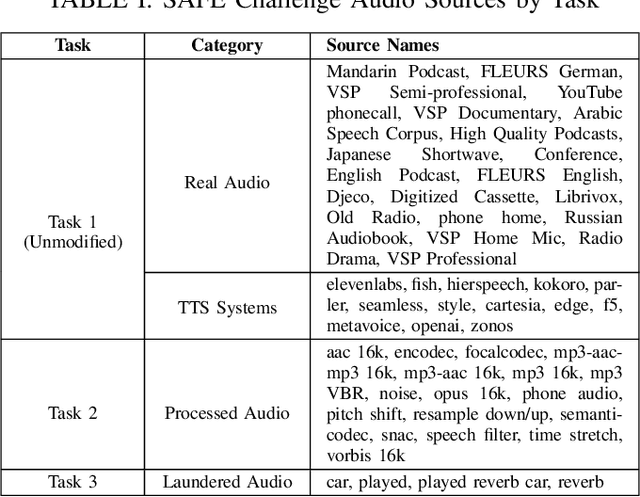
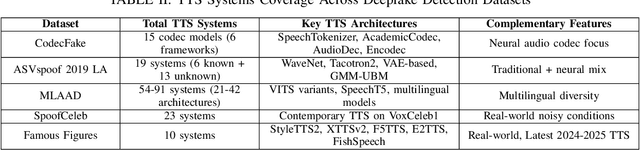
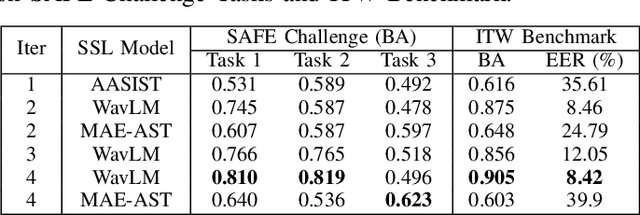
The SAFE Challenge evaluates synthetic speech detection across three tasks: unmodified audio, processed audio with compression artifacts, and laundered audio designed to evade detection. We systematically explore self-supervised learning (SSL) front-ends, training data compositions, and audio length configurations for robust deepfake detection. Our AASIST-based approach incorporates WavLM large frontend with RawBoost augmentation, trained on a multilingual dataset of 256,600 samples spanning 9 languages and over 70 TTS systems from CodecFake, MLAAD v5, SpoofCeleb, Famous Figures, and MAILABS. Through extensive experimentation with different SSL front-ends, three training data versions, and two audio lengths, we achieved second place in both Task 1 (unmodified audio detection) and Task 3 (laundered audio detection), demonstrating strong generalization and robustness.
Augmentation through Laundering Attacks for Audio Spoof Detection
Oct 01, 2024



Recent text-to-speech (TTS) developments have made voice cloning (VC) more realistic, affordable, and easily accessible. This has given rise to many potential abuses of this technology, including Joe Biden's New Hampshire deepfake robocall. Several methodologies have been proposed to detect such clones. However, these methodologies have been trained and evaluated on relatively clean databases. Recently, ASVspoof 5 Challenge introduced a new crowd-sourced database of diverse acoustic conditions including various spoofing attacks and codec conditions. This paper is our submission to the ASVspoof 5 Challenge and aims to investigate the performance of Audio Spoof Detection, trained using data augmentation through laundering attacks, on the ASVSpoof 5 database. The results demonstrate that our system performs worst on A18, A19, A20, A26, and A30 spoofing attacks and in the codec and compression conditions of C08, C09, and C10.
Is Audio Spoof Detection Robust to Laundering Attacks?
Aug 27, 2024
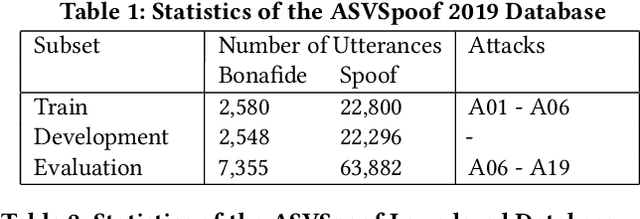

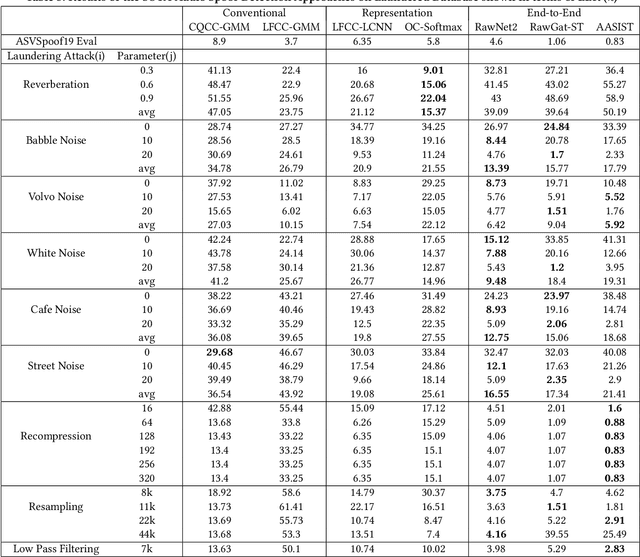
Voice-cloning (VC) systems have seen an exceptional increase in the realism of synthesized speech in recent years. The high quality of synthesized speech and the availability of low-cost VC services have given rise to many potential abuses of this technology. Several detection methodologies have been proposed over the years that can detect voice spoofs with reasonably good accuracy. However, these methodologies are mostly evaluated on clean audio databases, such as ASVSpoof 2019. This paper evaluates SOTA Audio Spoof Detection approaches in the presence of laundering attacks. In that regard, a new laundering attack database, called the ASVSpoof Laundering Database, is created. This database is based on the ASVSpoof 2019 (LA) eval database comprising a total of 1388.22 hours of audio recordings. Seven SOTA audio spoof detection approaches are evaluated on this laundered database. The results indicate that SOTA systems perform poorly in the presence of aggressive laundering attacks, especially reverberation and additive noise attacks. This suggests the need for robust audio spoof detection.
Protecting Voice-Controlled Devices against LASER Injection Attacks
Oct 13, 2023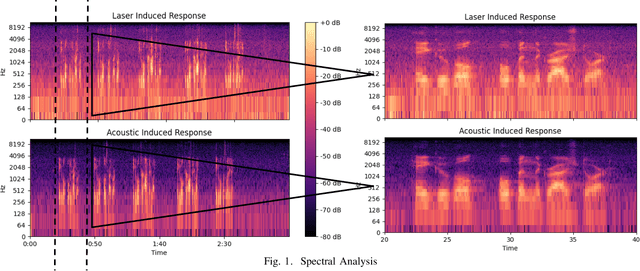
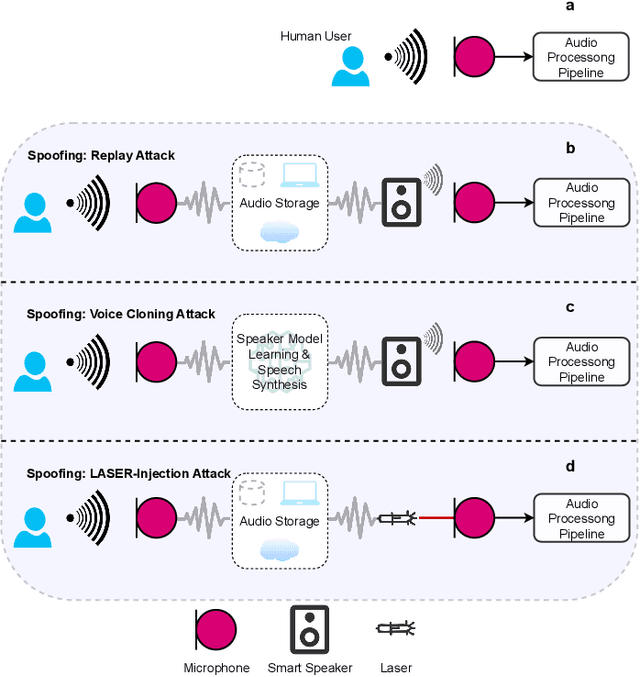
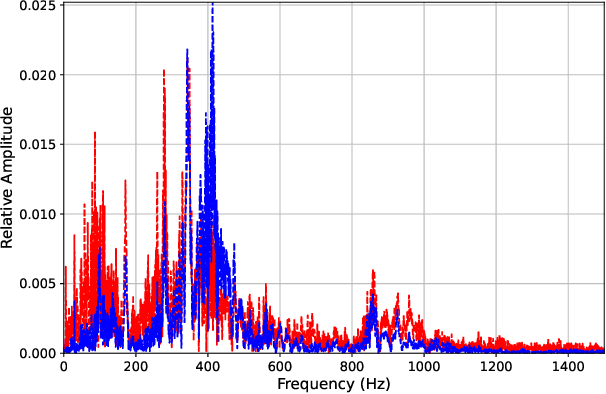
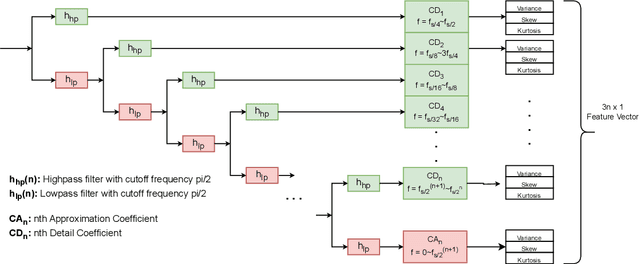
Voice-Controllable Devices (VCDs) have seen an increasing trend towards their adoption due to the small form factor of the MEMS microphones and their easy integration into modern gadgets. Recent studies have revealed that MEMS microphones are vulnerable to audio-modulated laser injection attacks. This paper aims to develop countermeasures to detect and prevent laser injection attacks on MEMS microphones. A time-frequency decomposition based on discrete wavelet transform (DWT) is employed to decompose microphone output audio signal into n + 1 frequency subbands to capture photo-acoustic related artifacts. Higher-order statistical features consisting of the first four moments of subband audio signals, e.g., variance, skew, and kurtosis are used to distinguish between acoustic and photo-acoustic responses. An SVM classifier is used to learn the underlying model that differentiates between an acoustic- and laser-induced (photo-acoustic) response in the MEMS microphone. The proposed framework is evaluated on a data set of 190 audios, consisting of 19 speakers. The experimental results indicate that the proposed framework is able to correctly classify $98\%$ of the acoustic- and laser-induced audio in a random data partition setting and $100\%$ of the audio in speaker-independent and text-independent data partition settings.