 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvMLP: Hierarchical Convolutional MLPs for Vision
Paper and Code
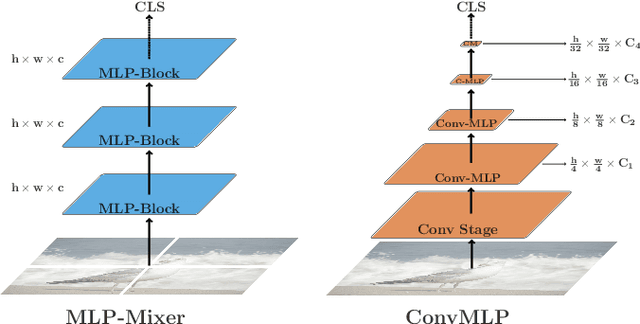



MLP-based architectures, which consist of a sequence of consecutive multi-layer perceptron blocks, have recently been found to reach comparable results to convolutional and transformer-based methods. However, most adopt spatial MLPs which take fixed dimension inputs, therefore making it difficult to apply them to downstream tasks, such as object detection and semantic segmentation. Moreover, single-stage designs further limit performance in other computer vision tasks and fully connected layers bear heavy computation. To tackle these problems, we propose ConvMLP: a hierarchical Convolutional MLP for visual recognition, which is a light-weight, stage-wise, co-design of convolution layers, and MLPs. In particular, ConvMLP-S achieves 76.8% top-1 accuracy on ImageNet-1k with 9M parameters and 2.4G MACs (15% and 19% of MLP-Mixer-B/16, respectively). Experiments on object detection and semantic segmentation further show that visual representation learned by ConvMLP can be seamlessly transferred and achieve competitive results with fewer parameters. Our code and pre-trained models are publicly available at https://github.com/SHI-Labs/Convolutional-MLPs.