 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Recommendation with Deliberative User Preference Alignment
Paper and Code
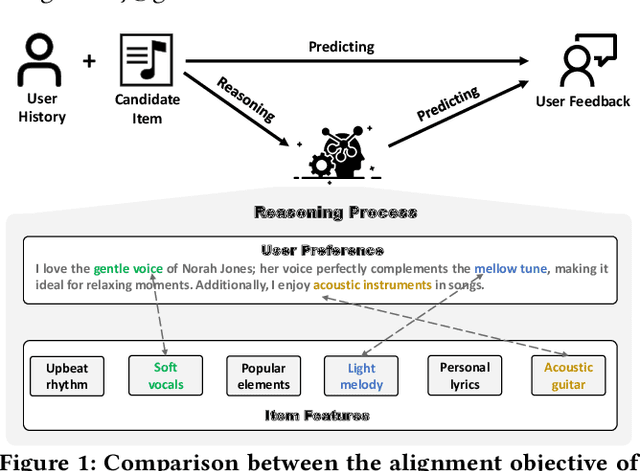
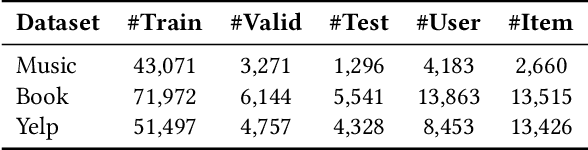
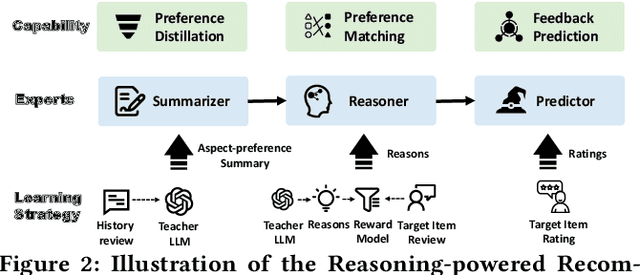
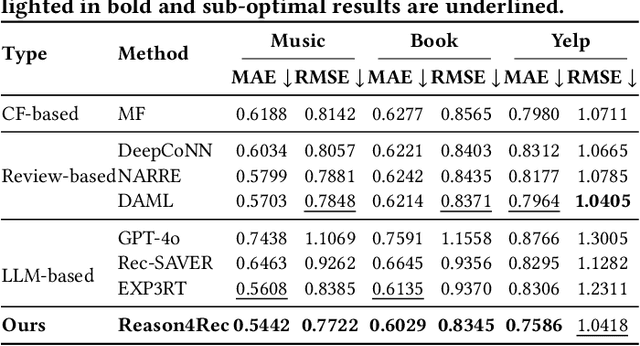
While recent advancements in aligning Large Language Models (LLMs) with recommendation tasks have shown great potential and promising performance overall, these aligned recommendation LLMs still face challenges in complex scenarios. This is primarily due to the current alignment approach focusing on optimizing LLMs to generate user feedback directly, without incorporating deliberation. To overcome this limitation and develop more reliable LLMs for recommendations, we propose a new Deliberative Recommendation task, which incorporates explicit reasoning about user preferences as an additional alignment goal. We then introduce the Deliberative User Preference Alignment framework, designed to enhance reasoning capabilities by utilizing verbalized user feedback in a step-wise manner to tackle this task. The framework employs collaborative step-wise experts and tailored training strategies for each expert. Experimental results across three real-world datasets demonstrate the rationality of the deliberative task formulation and the superior performance of the proposed framework in improving both prediction accuracy and reasoning quality.