 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Large Language Models Capacity to Annotate Journalistic Sourcing
Dec 30, 2024



Since the launch of ChatGPT in late 2022, the capacities of Large Language Models and their evaluation have been in constant discussion and evaluation both in academic research and in the industry. Scenarios and benchmarks have been developed in several areas such as law, medicine and math (Bommasani et al., 2023) and there is continuous evaluation of model variants. One area that has not received sufficient scenario development attention is journalism, and in particular journalistic sourcing and ethics. Journalism is a crucial truth-determination function in democracy (Vincent, 2023), and sourcing is a crucial pillar to all original journalistic output. Evaluating the capacities of LLMs to annotate stories for the different signals of sourcing and how reporters justify them is a crucial scenario that warrants a benchmark approach. It offers potential to build automated systems to contrast more transparent and ethically rigorous forms of journalism with everyday fare. In this paper we lay out a scenario to evaluate LLM performance on identifying and annotating sourcing in news stories on a five-category schema inspired from journalism studies (Gans, 2004). We offer the use case, our dataset and metrics and as the first step towards systematic benchmarking. Our accuracy findings indicate LLM-based approaches have more catching to do in identifying all the sourced statements in a story, and equally, in matching the type of sources. An even harder task is spotting source justifications.
DIANES: A DEI Audit Toolkit for News Sources
Mar 21, 2022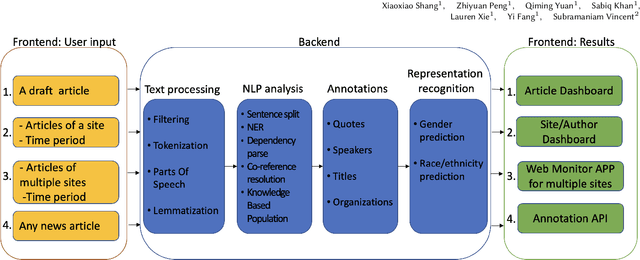
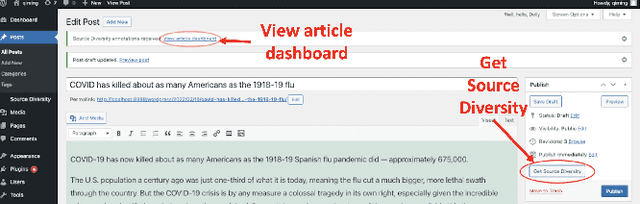
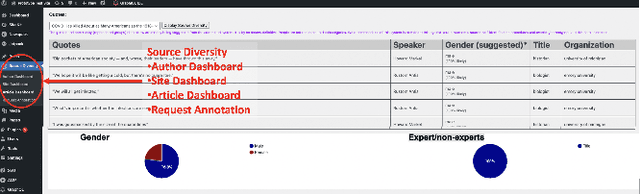
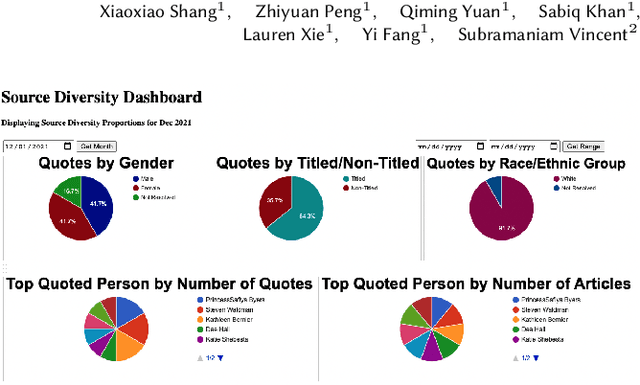
Professional news media organizations have always touted the importance that they give to multiple perspectives. However, in practice the traditional approach to all-sides has favored people in the dominant culture. Hence it has come under ethical critique under the new norms of diversity, equity, and inclusion (DEI). When DEI is applied to journalism, it goes beyond conventional notions of impartiality and bias and instead democratizes the journalistic practice of sourcing -- who is quoted or interviewed, who is not, how often, from which demographic group, gender, and so forth. There is currently no real-time or on-demand tool in the hands of reporters to analyze the persons they quote. In this paper, we present DIANES, a DEI Audit Toolkit for News Sources. It consists of a natural language processing pipeline on the backend to extract quotes, speakers, titles, and organizations from news articles in real time. On the frontend, DIANES offers the WordPress plugins, a Web monitor, and a DEI annotation API service, to help news media monitor their own quoting patterns and push themselves towards DEI norms.