 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToProVAR: Efficient Visual Autoregressive Modeling via Tri-Dimensional Entropy-Aware Semantic Analysis and Sparsity Optimization
Feb 26, 2026Visual Autoregressive(VAR) models enhance generation quality but face a critical efficiency bottleneck in later stages. In this paper, we present a novel optimization framework for VAR models that fundamentally differs from prior approaches such as FastVAR and SkipVAR. Instead of relying on heuristic skipping strategies, our method leverages attention entropy to characterize the semantic projections across different dimensions of the model architecture. This enables precise identification of parameter dynamics under varying token granularity levels, semantic scopes, and generation scales. Building on this analysis, we further uncover sparsity patterns along three critical dimensions-token, layer, and scale-and propose a set of fine-grained optimization strategies tailored to these patterns. Extensive evaluation demonstrates that our approach achieves aggressive acceleration of the generation process while significantly preserving semantic fidelity and fine details, outperforming traditional methods in both efficiency and quality. Experiments on Infinity-2B and Infinity-8B models demonstrate that ToProVAR achieves up to 3.4x acceleration with minimal quality loss, effectively mitigating the issues found in prior work. Our code will be made publicly available.
R2C2-Coder: Enhancing and Benchmarking Real-world Repository-level Code Completion Abilities of Code Large Language Models
Jun 04, 2024



Code completion models have made significant progress in recent years. Recently, repository-level code completion has drawn more attention in modern software development, and several baseline methods and benchmarks have been proposed. However, existing repository-level code completion methods often fall short of fully using the extensive context of a project repository, such as the intricacies of relevant files and class hierarchies. Besides, the existing benchmarks usually focus on limited code completion scenarios, which cannot reflect the repository-level code completion abilities well of existing methods. To address these limitations, we propose the R2C2-Coder to enhance and benchmark the real-world repository-level code completion abilities of code Large Language Models, where the R2C2-Coder includes a code prompt construction method R2C2-Enhance and a well-designed benchmark R2C2-Bench. Specifically, first, in R2C2-Enhance, we first construct the candidate retrieval pool and then assemble the completion prompt by retrieving from the retrieval pool for each completion cursor position. Second, based on R2C2 -Enhance, we can construct a more challenging and diverse R2C2-Bench with training, validation and test splits, where a context perturbation strategy is proposed to simulate the real-world repository-level code completion well. Extensive results on multiple benchmarks demonstrate the effectiveness of our R2C2-Coder.
Distributed Learning in Heterogeneous Environment: federated learning with adaptive aggregation and computation reduction
Feb 16, 2023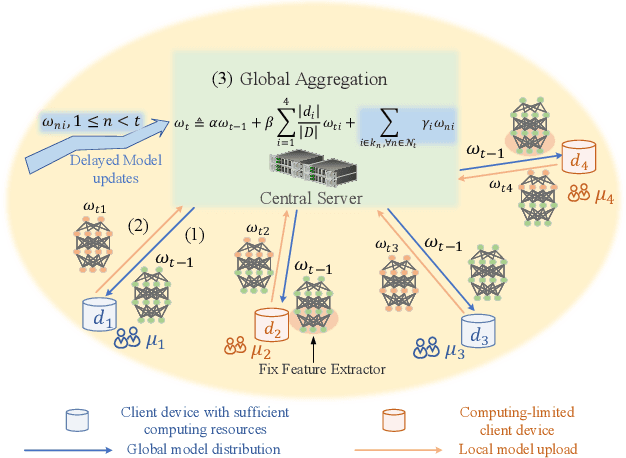
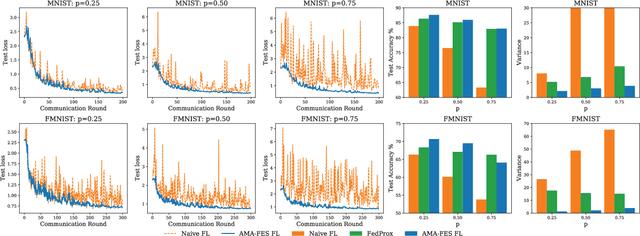
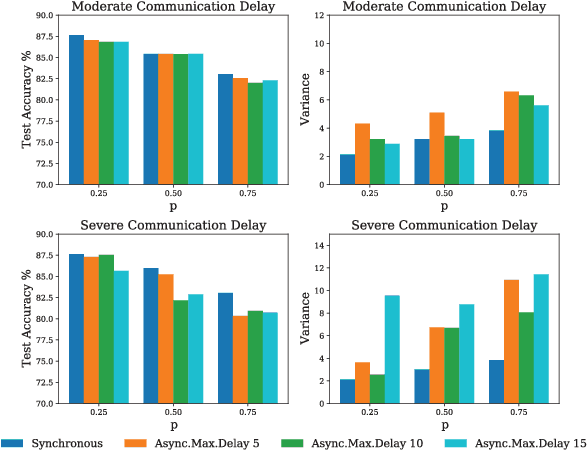
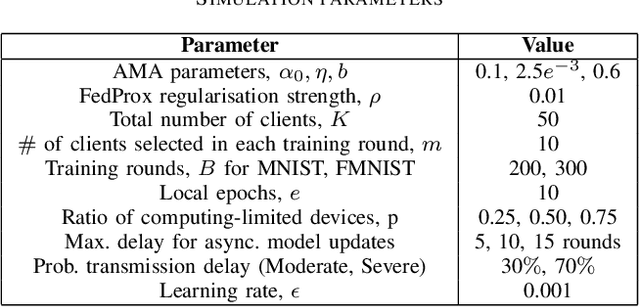
Although federated learning has achieved many breakthroughs recently, the heterogeneous nature of the learning environment greatly limits its performance and hinders its real-world applications. The heterogeneous data, time-varying wireless conditions and computing-limited devices are three main challenges, which often result in an unstable training process and degraded accuracy. Herein, we propose strategies to address these challenges. Targeting the heterogeneous data distribution, we propose a novel adaptive mixing aggregation (AMA) scheme that mixes the model updates from previous rounds with current rounds to avoid large model shifts and thus, maintain training stability. We further propose a novel staleness-based weighting scheme for the asynchronous model updates caused by the dynamic wireless environment. Lastly, we propose a novel CPU-friendly computation-reduction scheme based on transfer learning by sharing the feature extractor (FES) and letting the computing-limited devices update only the classifier. The simulation results show that the proposed framework outperforms existing state-of-the-art solutions and increases the test accuracy, and training stability by up to 2.38%, 93.10% respectively. Additionally, the proposed framework can tolerate communication delay of up to 15 rounds under a moderate delay environment without significant accuracy degradation.