 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-RAFT: Cross-Modal Non-Rigid Registration of Blue and White Light Neurosurgical Hyperspectral Images
Jul 10, 2025Integration of hyperspectral imaging into fluorescence-guided neurosurgery has the potential to improve surgical decision making by providing quantitative fluorescence measurements in real-time. Quantitative fluorescence requires paired spectral data in fluorescence (blue light) and reflectance (white light) mode. Blue and white image acquisition needs to be performed sequentially in a potentially dynamic surgical environment. A key component to the fluorescence quantification process is therefore the ability to find dense cross-modal image correspondences between two hyperspectral images taken under these drastically different lighting conditions. We address this challenge with the introduction of X-RAFT, a Recurrent All-Pairs Field Transforms (RAFT) optical flow model modified for cross-modal inputs. We propose using distinct image encoders for each modality pair, and fine-tune these in a self-supervised manner using flow-cycle-consistency on our neurosurgical hyperspectral data. We show an error reduction of 36.6% across our evaluation metrics when comparing to a naive baseline and 27.83% reduction compared to an existing cross-modal optical flow method (CrossRAFT). Our code and models will be made publicly available after the review process.
Scribble-Based Interactive Segmentation of Medical Hyperspectral Images
Aug 05, 2024

Hyperspectral imaging (HSI) is an advanced medical imaging modality that captures optical data across a broad spectral range, providing novel insights into the biochemical composition of tissues. HSI may enable precise differentiation between various tissue types and pathologies, making it particularly valuable for tumour detection, tissue classification, and disease diagnosis. Deep learning-based segmentation methods have shown considerable advancements, offering automated and accurate results. However, these methods face challenges with HSI datasets due to limited annotated data and discrepancies from hardware and acquisition techniques~\cite{clancy2020surgical,studier2023heiporspectral}. Variability in clinical protocols also leads to different definitions of structure boundaries. Interactive segmentation methods, utilizing user knowledge and clinical insights, can overcome these issues and achieve precise segmentation results \cite{zhao2013overview}. This work introduces a scribble-based interactive segmentation framework for medical hyperspectral images. The proposed method utilizes deep learning for feature extraction and a geodesic distance map generated from user-provided scribbles to obtain the segmentation results. The experiment results show that utilising the geodesic distance maps based on deep learning-extracted features achieved better segmentation results than geodesic distance maps directly generated from hyperspectral images, reconstructed RGB images, or Euclidean distance maps.
CholecInstanceSeg: A Tool Instance Segmentation Dataset for Laparoscopic Surgery
Jun 23, 2024In laparoscopic and robotic surgery, precise tool instance segmentation is an essential technology for advanced computer-assisted interventions. Although publicly available procedures of routine surgeries exist, they often lack comprehensive annotations for tool instance segmentation. Additionally, the majority of standard datasets for tool segmentation are derived from porcine(pig) surgeries. To address this gap, we introduce CholecInstanceSeg, the largest open-access tool instance segmentation dataset to date. Derived from the existing CholecT50 and Cholec80 datasets, CholecInstanceSeg provides novel annotations for laparoscopic cholecystectomy procedures in patients. Our dataset comprises 41.9k annotated frames extracted from 85 clinical procedures and 64.4k tool instances, each labelled with semantic masks and instance IDs. To ensure the reliability of our annotations, we perform extensive quality control, conduct label agreement statistics, and benchmark the segmentation results with various instance segmentation baselines. CholecInstanceSeg aims to advance the field by offering a comprehensive and high-quality open-access dataset for the development and evaluation of tool instance segmentation algorithms.
Transferring Relative Monocular Depth to Surgical Vision with Temporal Consistency
Mar 11, 2024Relative monocular depth, inferring depth up to shift and scale from a single image, is an active research topic. Recent deep learning models, trained on large and varied meta-datasets, now provide excellent performance in the domain of natural images. However, few datasets exist which provide ground truth depth for endoscopic images, making training such models from scratch unfeasible. This work investigates the transfer of these models into the surgical domain, and presents an effective and simple way to improve on standard supervision through the use of temporal consistency self-supervision. We show temporal consistency significantly improves supervised training alone when transferring to the low-data regime of endoscopy, and outperforms the prevalent self-supervision technique for this task. In addition we show our method drastically outperforms the state-of-the-art method from within the domain of endoscopy. We also release our code, model and ensembled meta-dataset, Meta-MED, establishing a strong benchmark for future work.
SegMatch: A semi-supervised learning method for surgical instrument segmentation
Aug 09, 2023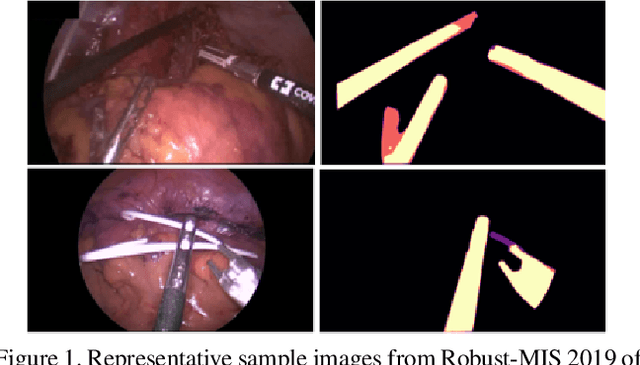
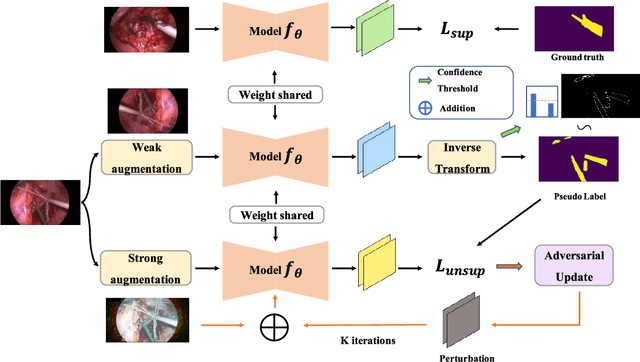
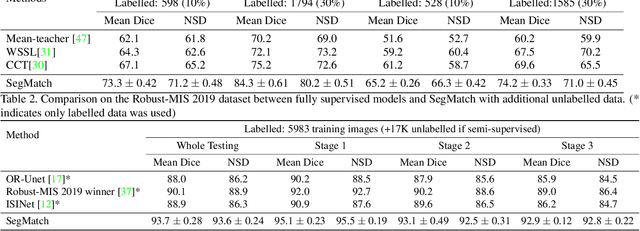
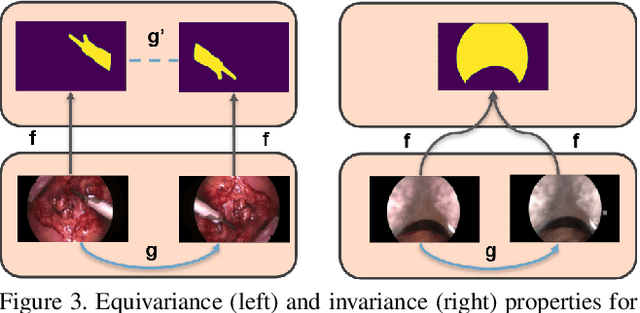
Surgical instrument segmentation is recognised as a key enabler to provide advanced surgical assistance and improve computer assisted interventions. In this work, we propose SegMatch, a semi supervised learning method to reduce the need for expensive annotation for laparoscopic and robotic surgical images. SegMatch builds on FixMatch, a widespread semi supervised classification pipeline combining consistency regularization and pseudo labelling, and adapts it for the purpose of segmentation. In our proposed SegMatch, the unlabelled images are weakly augmented and fed into the segmentation model to generate a pseudo-label to enforce the unsupervised loss against the output of the model for the adversarial augmented image on the pixels with a high confidence score. Our adaptation for segmentation tasks includes carefully considering the equivariance and invariance properties of the augmentation functions we rely on. To increase the relevance of our augmentations, we depart from using only handcrafted augmentations and introduce a trainable adversarial augmentation strategy. Our algorithm was evaluated on the MICCAI Instrument Segmentation Challenge datasets Robust-MIS 2019 and EndoVis 2017. Our results demonstrate that adding unlabelled data for training purposes allows us to surpass the performance of fully supervised approaches which are limited by the availability of training data in these challenges. SegMatch also outperforms a range of state-of-the-art semi-supervised learning semantic segmentation models in different labelled to unlabelled data ratios.
Deep Reinforcement Learning Based System for Intraoperative Hyperspectral Video Autofocusing
Jul 21, 2023Hyperspectral imaging (HSI) captures a greater level of spectral detail than traditional optical imaging, making it a potentially valuable intraoperative tool when precise tissue differentiation is essential. Hardware limitations of current optical systems used for handheld real-time video HSI result in a limited focal depth, thereby posing usability issues for integration of the technology into the operating room. This work integrates a focus-tunable liquid lens into a video HSI exoscope, and proposes novel video autofocusing methods based on deep reinforcement learning. A first-of-its-kind robotic focal-time scan was performed to create a realistic and reproducible testing dataset. We benchmarked our proposed autofocus algorithm against traditional policies, and found our novel approach to perform significantly ($p<0.05$) better than traditional techniques ($0.070\pm.098$ mean absolute focal error compared to $0.146\pm.148$). In addition, we performed a blinded usability trial by having two neurosurgeons compare the system with different autofocus policies, and found our novel approach to be the most favourable, making our system a desirable addition for intraoperative HSI.
MONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022



Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
Rapid and robust endoscopic content area estimation: A lean GPU-based pipeline and curated benchmark dataset
Oct 26, 2022Endoscopic content area refers to the informative area enclosed by the dark, non-informative, border regions present in most endoscopic footage. The estimation of the content area is a common task in endoscopic image processing and computer vision pipelines. Despite the apparent simplicity of the problem, several factors make reliable real-time estimation surprisingly challenging. The lack of rigorous investigation into the topic combined with the lack of a common benchmark dataset for this task has been a long-lasting issue in the field. In this paper, we propose two variants of a lean GPU-based computational pipeline combining edge detection and circle fitting. The two variants differ by relying on handcrafted features, and learned features respectively to extract content area edge point candidates. We also present a first-of-its-kind dataset of manually annotated and pseudo-labelled content areas across a range of surgical indications. To encourage further developments, the curated dataset, and an implementation of both algorithms, has been made public (https://doi.org/10.7303/syn32148000, https://github.com/charliebudd/torch-content-area). We compare our proposed algorithm with a state-of-the-art U-Net-based approach and demonstrate significant improvement in terms of both accuracy (Hausdorff distance: 6.3 px versus 118.1 px) and computational time (Average runtime per frame: 0.13 ms versus 11.2 ms).