 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubset-Contrastive Multi-Omics Network Embedding
Apr 15, 2025



Motivation: Network-based analyses of omics data are widely used, and while many of these methods have been adapted to single-cell scenarios, they often remain memory- and space-intensive. As a result, they are better suited to batch data or smaller datasets. Furthermore, the application of network-based methods in multi-omics often relies on similarity-based networks, which lack structurally-discrete topologies. This limitation may reduce the effectiveness of graph-based methods that were initially designed for topologies with better defined structures. Results: We propose Subset-Contrastive multi-Omics Network Embedding (SCONE), a method that employs contrastive learning techniques on large datasets through a scalable subgraph contrastive approach. By exploiting the pairwise similarity basis of many network-based omics methods, we transformed this characteristic into a strength, developing an approach that aims to achieve scalable and effective analysis. Our method demonstrates synergistic omics integration for cell type clustering in single-cell data. Additionally, we evaluate its performance in a bulk multi-omics integration scenario, where SCONE performs comparable to the state-of-the-art despite utilising limited views of the original data. We anticipate that our findings will motivate further research into the use of subset contrastive methods for omics data.
Surg-3M: A Dataset and Foundation Model for Perception in Surgical Settings
Mar 25, 2025Advancements in computer-assisted surgical procedures heavily rely on accurate visual data interpretation from camera systems used during surgeries. Traditional open-access datasets focusing on surgical procedures are often limited by their small size, typically consisting of fewer than 100 videos with less than 100K images. To address these constraints, a new dataset called Surg-3M has been compiled using a novel aggregation pipeline that collects high-resolution videos from online sources. Featuring an extensive collection of over 4K surgical videos and more than 3 million high-quality images from multiple procedure types, Surg-3M offers a comprehensive resource surpassing existing alternatives in size and scope, including two novel tasks. To demonstrate the effectiveness of this dataset, we present SurgFM, a self-supervised foundation model pretrained on Surg-3M that achieves impressive results in downstream tasks such as surgical phase recognition, action recognition, and tool presence detection. Combining key components from ConvNeXt, DINO, and an innovative augmented distillation method, SurgFM exhibits exceptional performance compared to specialist architectures across various benchmarks. Our experimental results show that SurgFM outperforms state-of-the-art models in multiple downstream tasks, including significant gains in surgical phase recognition (+8.9pp, +4.7pp, and +3.9pp of Jaccard in AutoLaparo, M2CAI16, and Cholec80), action recognition (+3.1pp of mAP in CholecT50) and tool presence detection (+4.6pp of mAP in Cholec80). Moreover, even when using only half of the data, SurgFM outperforms state-of-the-art models in AutoLaparo and achieves state-of-the-art performance in Cholec80. Both Surg-3M and SurgFM have significant potential to accelerate progress towards developing autonomous robotic surgery systems.
Enhancing Generalized Few-Shot Semantic Segmentation via Effective Knowledge Transfer
Dec 20, 2024
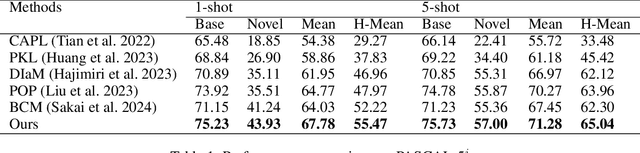


Generalized few-shot semantic segmentation (GFSS) aims to segment objects of both base and novel classes, using sufficient samples of base classes and few samples of novel classes. Representative GFSS approaches typically employ a two-phase training scheme, involving base class pre-training followed by novel class fine-tuning, to learn the classifiers for base and novel classes respectively. Nevertheless, distribution gap exists between base and novel classes in this process. To narrow this gap, we exploit effective knowledge transfer from base to novel classes. First, a novel prototype modulation module is designed to modulate novel class prototypes by exploiting the correlations between base and novel classes. Second, a novel classifier calibration module is proposed to calibrate the weight distribution of the novel classifier according to that of the base classifier. Furthermore, existing GFSS approaches suffer from a lack of contextual information for novel classes due to their limited samples, we thereby introduce a context consistency learning scheme to transfer the contextual knowledge from base to novel classes. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ demonstrate that our approach significantly enhances the state of the art in the GFSS setting. The code is available at: https://github.com/HHHHedy/GFSS-EKT.
Incorporating Prior Knowledge in Deep Learning Models via Pathway Activity Autoencoders
Jun 09, 2023



Motivation: Despite advances in the computational analysis of high-throughput molecular profiling assays (e.g. transcriptomics), a dichotomy exists between methods that are simple and interpretable, and ones that are complex but with lower degree of interpretability. Furthermore, very few methods deal with trying to translate interpretability in biologically relevant terms, such as known pathway cascades. Biological pathways reflecting signalling events or metabolic conversions are Small improvements or modifications of existing algorithms will generally not be suitable, unless novel biological results have been predicted and verified. Determining which pathways are implicated in disease and incorporating such pathway data as prior knowledge may enhance predictive modelling and personalised strategies for diagnosis, treatment and prevention of disease. Results: We propose a novel prior-knowledge-based deep auto-encoding framework, PAAE, together with its accompanying generative variant, PAVAE, for RNA-seq data in cancer. Through comprehensive comparisons among various learning models, we show that, despite having access to a smaller set of features, our PAAE and PAVAE models achieve better out-of-set reconstruction results compared to common methodologies. Furthermore, we compare our model with equivalent baselines on a classification task and show that they achieve better results than models which have access to the full input gene set. Another result is that using vanilla variational frameworks might negatively impact both reconstruction outputs as well as classification performance. Finally, our work directly contributes by providing comprehensive interpretability analyses on our models on top of improving prognostication for translational medicine.
Multi-Omic Data Integration and Feature Selection for Survival-based Patient Stratification via Supervised Concrete Autoencoders
Jun 27, 2022



Cancer is a complex disease with significant social and economic impact. Advancements in high-throughput molecular assays and the reduced cost for performing high-quality multi-omics measurements have fuelled insights through machine learning . Previous studies have shown promise on using multiple omic layers to predict survival and stratify cancer patients. In this paper, we developed a Supervised Autoencoder (SAE) model for survival-based multi-omic integration which improves upon previous work, and report a Concrete Supervised Autoencoder model (CSAE), which uses feature selection to jointly reconstruct the input features as well as predict survival. Our experiments show that our models outperform or are on par with some of the most commonly used baselines, while either providing a better survival separation (SAE) or being more interpretable (CSAE). We also perform a feature selection stability analysis on our models and notice that there is a power-law relationship with features which are commonly associated with survival. The code for this project is available at: https://github.com/phcavelar/coxae