 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany tasks make light work: Learning to localise medical anomalies from multiple synthetic tasks
Jul 03, 2023There is a growing interest in single-class modelling and out-of-distribution detection as fully supervised machine learning models cannot reliably identify classes not included in their training. The long tail of infinitely many out-of-distribution classes in real-world scenarios, e.g., for screening, triage, and quality control, means that it is often necessary to train single-class models that represent an expected feature distribution, e.g., from only strictly healthy volunteer data. Conventional supervised machine learning would require the collection of datasets that contain enough samples of all possible diseases in every imaging modality, which is not realistic. Self-supervised learning methods with synthetic anomalies are currently amongst the most promising approaches, alongside generative auto-encoders that analyse the residual reconstruction error. However, all methods suffer from a lack of structured validation, which makes calibration for deployment difficult and dataset-dependant. Our method alleviates this by making use of multiple visually-distinct synthetic anomaly learning tasks for both training and validation. This enables more robust training and generalisation. With our approach we can readily outperform state-of-the-art methods, which we demonstrate on exemplars in brain MRI and chest X-rays. Code is available at https://github.com/matt-baugh/many-tasks-make-light-work .
Confidence-Aware and Self-Supervised Image Anomaly Localisation
Mar 23, 2023Universal anomaly detection still remains a challenging problem in machine learning and medical image analysis. It is possible to learn an expected distribution from a single class of normative samples, e.g., through epistemic uncertainty estimates, auto-encoding models, or from synthetic anomalies in a self-supervised way. The performance of self-supervised anomaly detection approaches is still inferior compared to methods that use examples from known unknown classes to shape the decision boundary. However, outlier exposure methods often do not identify unknown unknowns. Here we discuss an improved self-supervised single-class training strategy that supports the approximation of probabilistic inference with loosen feature locality constraints. We show that up-scaling of gradients with histogram-equalised images is beneficial for recently proposed self-supervision tasks. Our method is integrated into several out-of-distribution (OOD) detection models and we show evidence that our method outperforms the state-of-the-art on various benchmark datasets. Source code will be publicly available by the time of the conference.
Adnexal Mass Segmentation with Ultrasound Data Synthesis
Sep 25, 2022Ovarian cancer is the most lethal gynaecological malignancy. The disease is most commonly asymptomatic at its early stages and its diagnosis relies on expert evaluation of transvaginal ultrasound images. Ultrasound is the first-line imaging modality for characterising adnexal masses, it requires significant expertise and its analysis is subjective and labour-intensive, therefore open to error. Hence, automating processes to facilitate and standardise the evaluation of scans is desired in clinical practice. Using supervised learning, we have demonstrated that segmentation of adnexal masses is possible, however, prevalence and label imbalance restricts the performance on under-represented classes. To mitigate this we apply a novel pathology-specific data synthesiser. We create synthetic medical images with their corresponding ground truth segmentations by using Poisson image editing to integrate less common masses into other samples. Our approach achieves the best performance across all classes, including an improvement of up to 8% when compared with nnU-Net baseline approaches.
nnOOD: A Framework for Benchmarking Self-supervised Anomaly Localisation Methods
Sep 02, 2022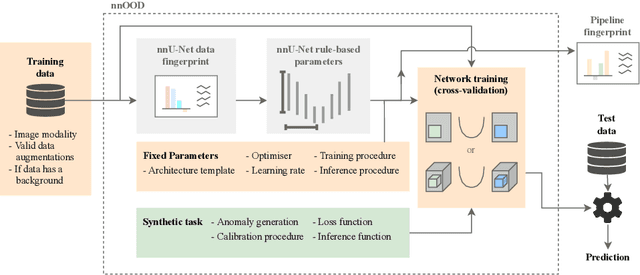

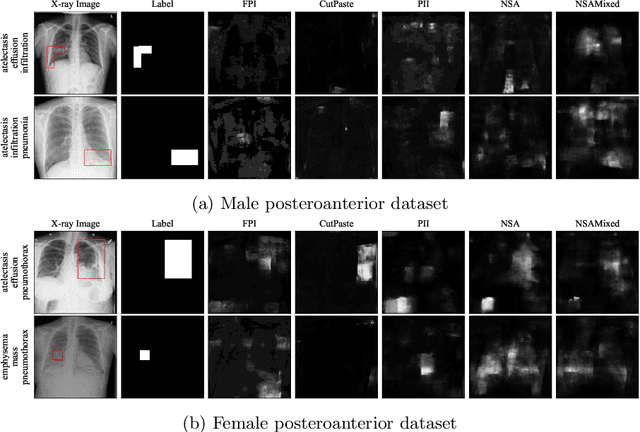
The wide variety of in-distribution and out-of-distribution data in medical imaging makes universal anomaly detection a challenging task. Recently a number of self-supervised methods have been developed that train end-to-end models on healthy data augmented with synthetic anomalies. However, it is difficult to compare these methods as it is not clear whether gains in performance are from the task itself or the training pipeline around it. It is also difficult to assess whether a task generalises well for universal anomaly detection, as they are often only tested on a limited range of anomalies. To assist with this we have developed nnOOD, a framework that adapts nnU-Net to allow for comparison of self-supervised anomaly localisation methods. By isolating the synthetic, self-supervised task from the rest of the training process we perform a more faithful comparison of the tasks, whilst also making the workflow for evaluating over a given dataset quick and easy. Using this we have implemented the current state-of-the-art tasks and evaluated them on a challenging X-ray dataset.
Self-Supervised Out-of-Distribution Detection and Localization with Natural Synthetic Anomalies (NSA)
Sep 30, 2021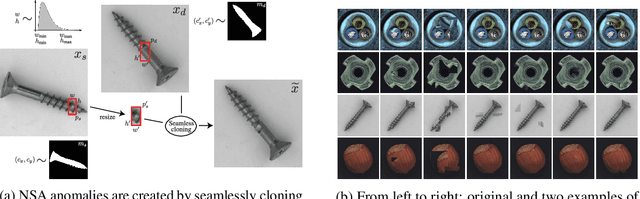
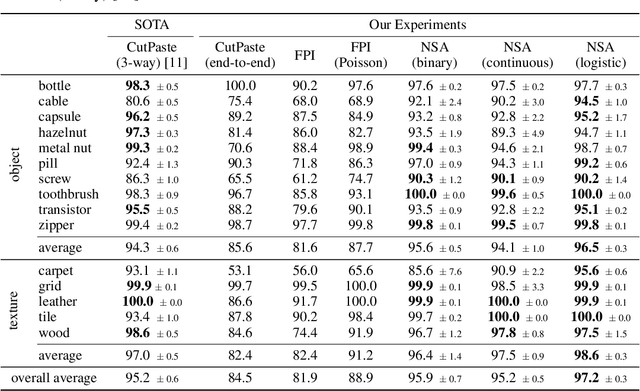
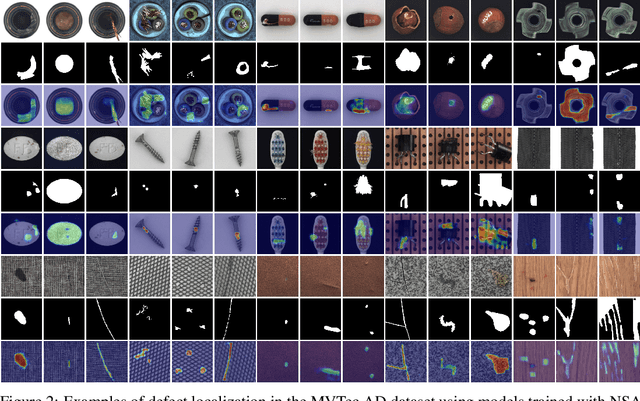
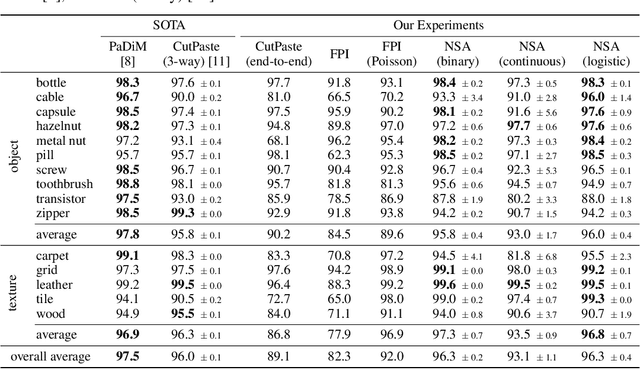
We introduce a new self-supervised task, NSA, for training an end-to-end model for anomaly detection and localization using only normal data. NSA uses Poisson image editing to seamlessly blend scaled patches of various sizes from separate images. This creates a wide range of synthetic anomalies which are more similar to natural sub-image irregularities than previous data-augmentation strategies for self-supervised anomaly detection. We evaluate the proposed method using natural and medical images. Our experiments with the MVTec AD dataset show that a model trained to localize NSA anomalies generalizes well to detecting real-world a priori unknown types of manufacturing defects. Our method achieves an overall detection AUROC of 97.2 outperforming all previous methods that learn from scratch without pre-training datasets.
Detecting Hypo-plastic Left Heart Syndrome in Fetal Ultrasound via Disease-specific Atlas Maps
Jul 06, 2021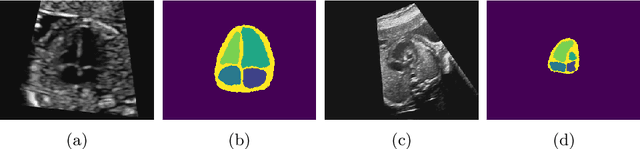
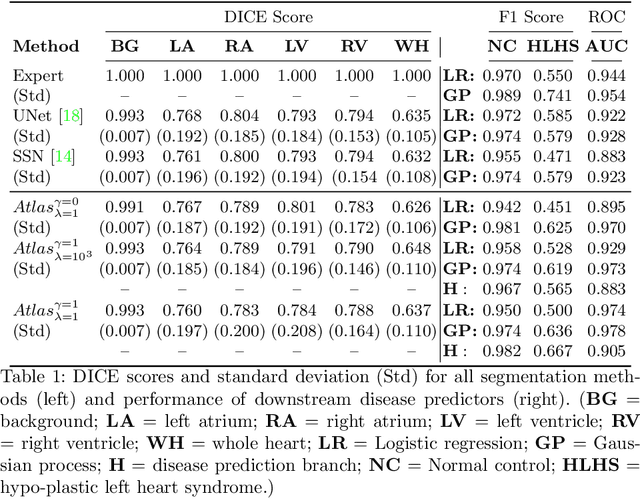

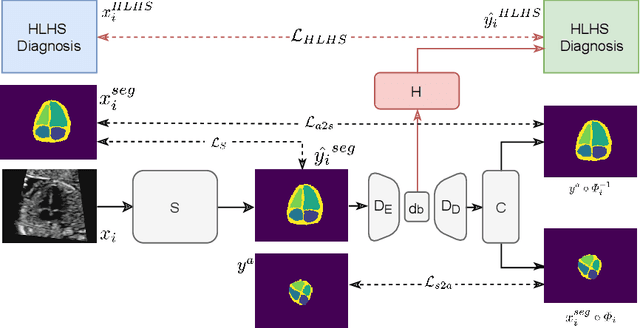
Fetal ultrasound screening during pregnancy plays a vital role in the early detection of fetal malformations which have potential long-term health impacts. The level of skill required to diagnose such malformations from live ultrasound during examination is high and resources for screening are often limited. We present an interpretable, atlas-learning segmentation method for automatic diagnosis of Hypo-plastic Left Heart Syndrome (HLHS) from a single `4 Chamber Heart' view image. We propose to extend the recently introduced Image-and-Spatial Transformer Networks (Atlas-ISTN) into a framework that enables sensitising atlas generation to disease. In this framework we can jointly learn image segmentation, registration, atlas construction and disease prediction while providing a maximum level of clinical interpretability compared to direct image classification methods. As a result our segmentation allows diagnoses competitive with expert-derived manual diagnosis and yields an AUC-ROC of 0.978 (1043 cases for training, 260 for validation and 325 for testing).
Detecting Outliers with Poisson Image Interpolation
Jul 06, 2021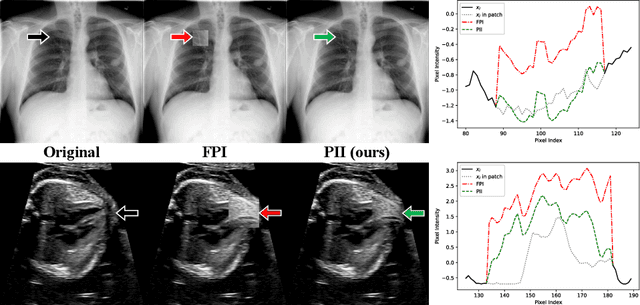
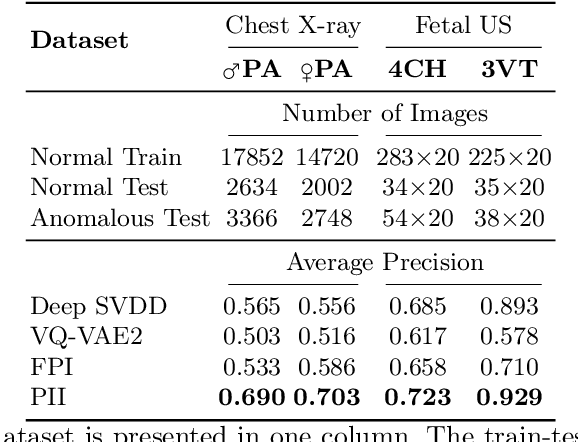
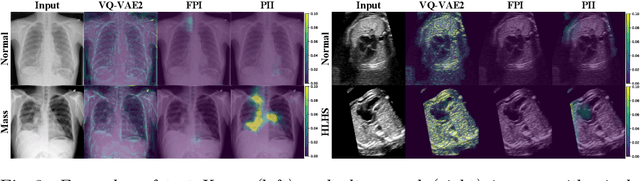
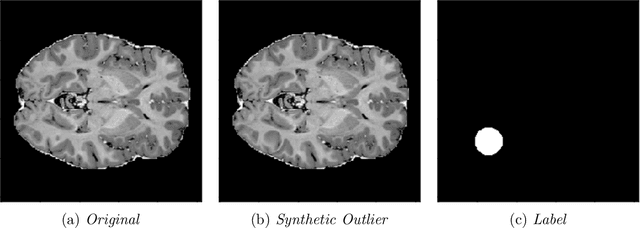
Supervised learning of every possible pathology is unrealistic for many primary care applications like health screening. Image anomaly detection methods that learn normal appearance from only healthy data have shown promising results recently. We propose an alternative to image reconstruction-based and image embedding-based methods and propose a new self-supervised method to tackle pathological anomaly detection. Our approach originates in the foreign patch interpolation (FPI) strategy that has shown superior performance on brain MRI and abdominal CT data. We propose to use a better patch interpolation strategy, Poisson image interpolation (PII), which makes our method suitable for applications in challenging data regimes. PII outperforms state-of-the-art methods by a good margin when tested on surrogate tasks like identifying common lung anomalies in chest X-rays or hypo-plastic left heart syndrome in prenatal, fetal cardiac ultrasound images. Code available at https://github.com/jemtan/PII.
Learning normal appearance for fetal anomaly screening: Application to the unsupervised detection of Hypoplastic Left Heart Syndrome
Nov 15, 2020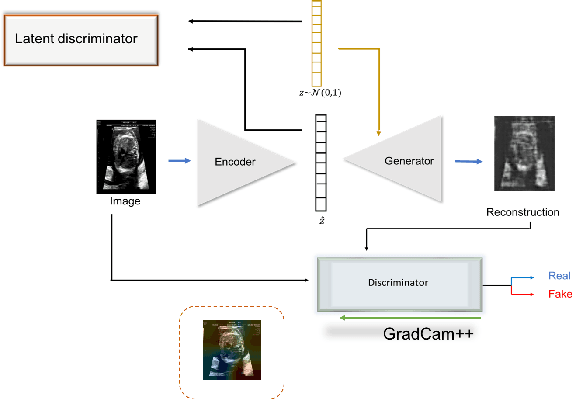
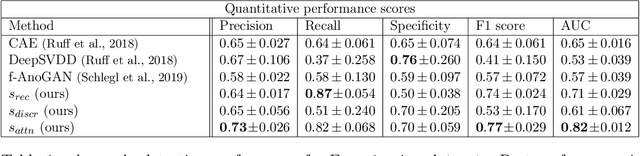
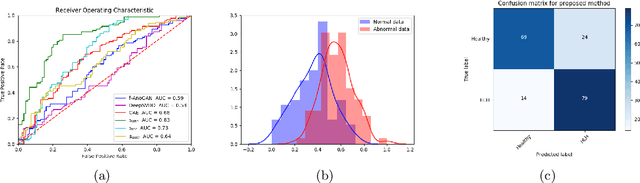
Congenital heart disease is considered as one the most common groups of congenital malformations which affects $6-11$ per $1000$ newborns. In this work, an automated framework for detection of cardiac anomalies during ultrasound screening is proposed and evaluated on the example of Hypoplastic Left Heart Syndrome (HLHS), a sub-category of congenital heart disease. We propose an unsupervised approach that learns healthy anatomy exclusively from clinically confirmed normal control patients. We evaluate a number of known anomaly detection frameworks together with a new model architecture based on the $\alpha$-GAN network and find evidence that the proposed model performs significantly better than the state-of-the-art in image-based anomaly detection, yielding average $0.81$ AUC \emph{and} a better robustness towards initialisation compared to previous works.
Detecting Outliers with Foreign Patch Interpolation
Nov 09, 2020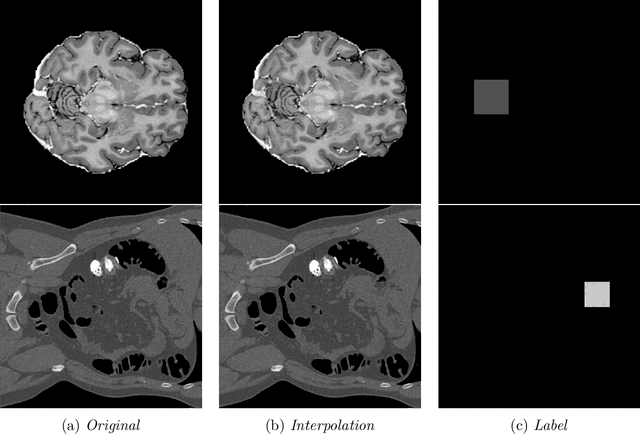
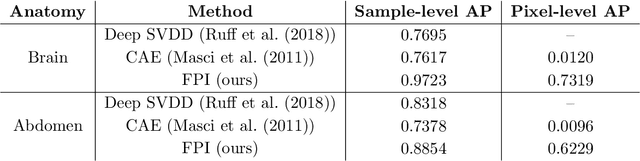
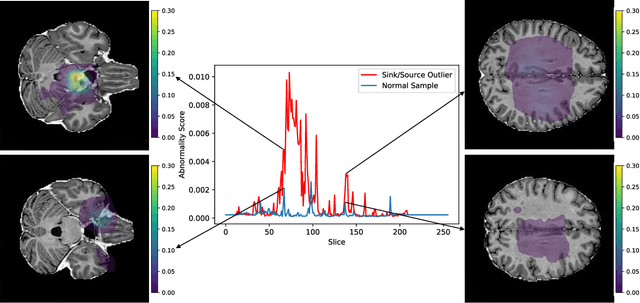
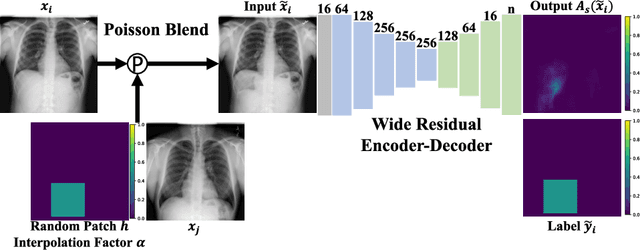
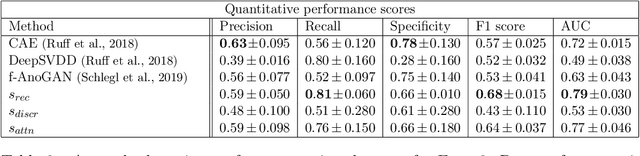
In medical imaging, outliers can contain hypo/hyper-intensities, minor deformations, or completely altered anatomy. To detect these irregularities it is helpful to learn the features present in both normal and abnormal images. However this is difficult because of the wide range of possible abnormalities and also the number of ways that normal anatomy can vary naturally. As such, we leverage the natural variations in normal anatomy to create a range of synthetic abnormalities. Specifically, the same patch region is extracted from two independent samples and replaced with an interpolation between both patches. The interpolation factor, patch size, and patch location are randomly sampled from uniform distributions. A wide residual encoder decoder is trained to give a pixel-wise prediction of the patch and its interpolation factor. This encourages the network to learn what features to expect normally and to identify where foreign patterns have been introduced. The estimate of the interpolation factor lends itself nicely to the derivation of an outlier score. Meanwhile the pixel-wise output allows for pixel- and subject- level predictions using the same model.
Automated Detection of Congenital Heart Disease in Fetal Ultrasound Screening
Aug 18, 2020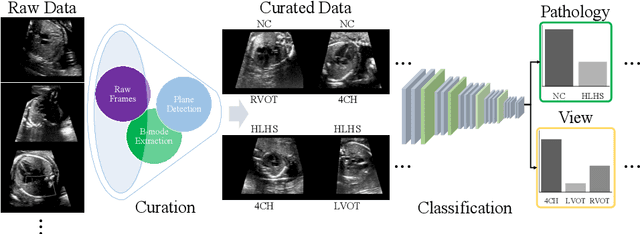
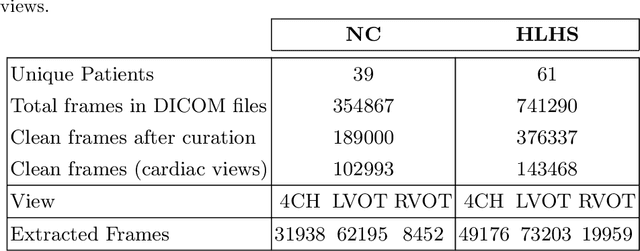
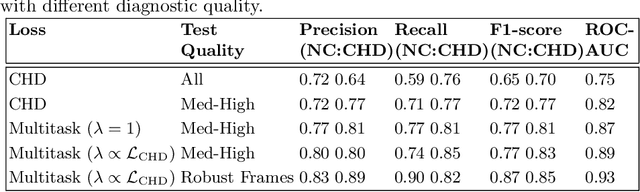
Prenatal screening with ultrasound can lower neonatal mortality significantly for selected cardiac abnormalities. However, the need for human expertise, coupled with the high volume of screening cases, limits the practically achievable detection rates. In this paper we discuss the potential for deep learning techniques to aid in the detection of congenital heart disease (CHD) in fetal ultrasound. We propose a pipeline for automated data curation and classification. During both training and inference, we exploit an auxiliary view classification task to bias features toward relevant cardiac structures. This bias helps to improve in F1-scores from 0.72 and 0.77 to 0.87 and 0.85 for healthy and CHD classes respectively.