 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM2Latent: Text-to-facial image generation and editing in GANs with multimodal assistance
Paper and Code
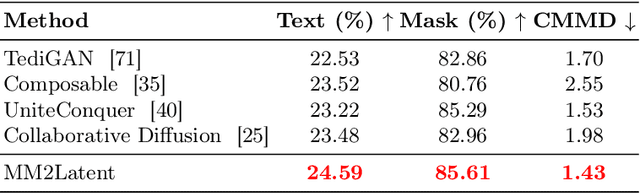
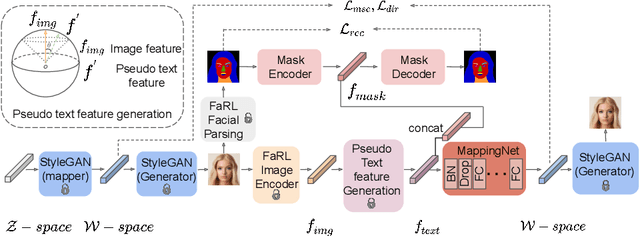
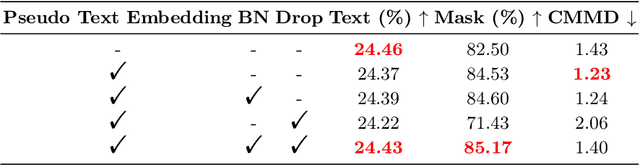

Generating human portraits is a hot topic in the image generation area, e.g. mask-to-face generation and text-to-face generation. However, these unimodal generation methods lack controllability in image generation. Controllability can be enhanced by exploring the advantages and complementarities of various modalities. For instance, we can utilize the advantages of text in controlling diverse attributes and masks in controlling spatial locations. Current state-of-the-art methods in multimodal generation face limitations due to their reliance on extensive hyperparameters, manual operations during the inference stage, substantial computational demands during training and inference, or inability to edit real images. In this paper, we propose a practical framework - MM2Latent - for multimodal image generation and editing. We use StyleGAN2 as our image generator, FaRL for text encoding, and train an autoencoders for spatial modalities like mask, sketch and 3DMM. We propose a strategy that involves training a mapping network to map the multimodal input into the w latent space of StyleGAN. The proposed framework 1) eliminates hyperparameters and manual operations in the inference stage, 2) ensures fast inference speeds, and 3) enables the editing of real images. Extensive experiments demonstrate that our method exhibits superior performance in multimodal image generation, surpassing recent GAN- and diffusion-based methods. Also, it proves effective in multimodal image editing and is faster than GAN- and diffusion-based methods. We make the code publicly available at: https://github.com/Open-Debin/MM2Latent