 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeframe attention networks for facial expression recognition in videos
Paper and Code
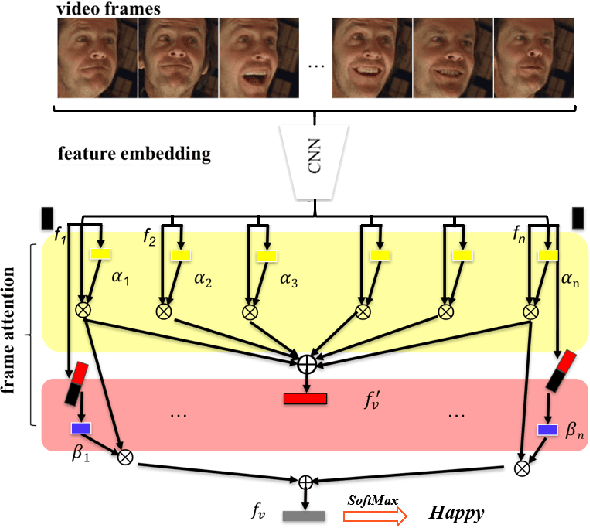

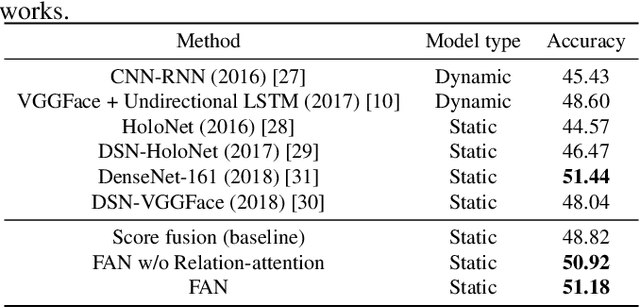
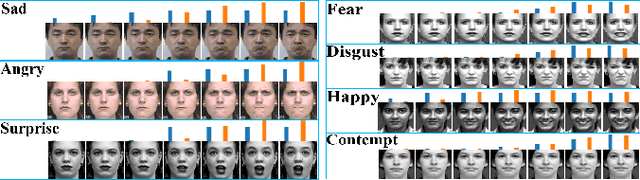
The video-based facial expression recognition aims to classify a given video into several basic emotions. How to integrate facial features of individual frames is crucial for this task. In this paper, we propose the Frame Attention Networks (FAN), to automatically highlight some discriminative frames in an end-to-end framework. The network takes a video with a variable number of face images as its input and produces a fixed-dimension representation. The whole network is composed of two modules. The feature embedding module is a deep Convolutional Neural Network (CNN) which embeds face images into feature vectors. The frame attention module learns multiple attention weights which are used to adaptively aggregate the feature vectors to form a single discriminative video representation. We conduct extensive experiments on CK+ and AFEW8.0 datasets. Our proposed FAN shows superior performance compared to other CNN based methods and achieves state-of-the-art performance on CK+.