 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCemiFace: Center-based Semi-hard Synthetic Face Generation for Face Recognition
Paper and Code
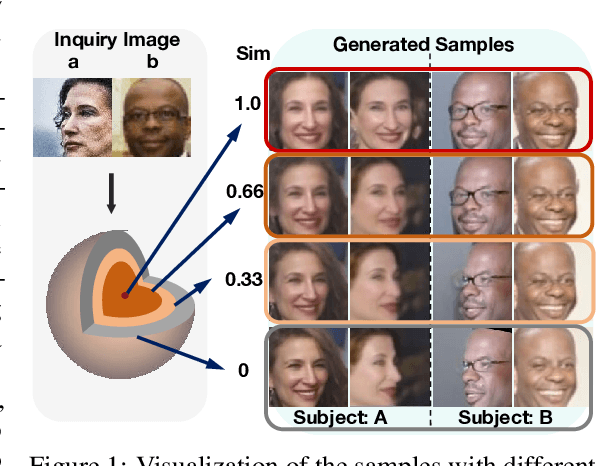
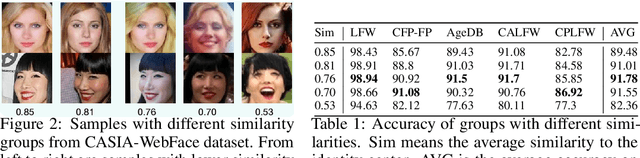
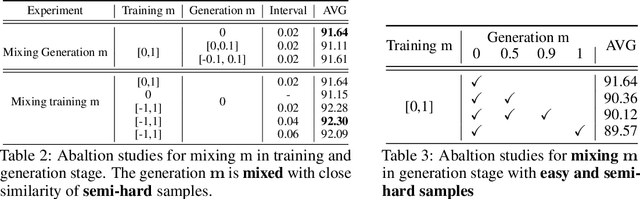
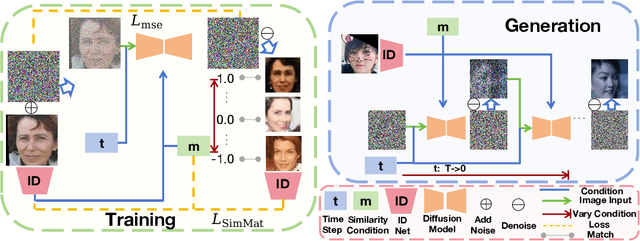
Privacy issue is a main concern in developing face recognition techniques. Although synthetic face images can partially mitigate potential legal risks while maintaining effective face recognition (FR) performance, FR models trained by face images synthesized by existing generative approaches frequently suffer from performance degradation problems due to the insufficient discriminative quality of these synthesized samples. In this paper, we systematically investigate what contributes to solid face recognition model training, and reveal that face images with certain degree of similarities to their identity centers show great effectiveness in the performance of trained FR models. Inspired by this, we propose a novel diffusion-based approach (namely Center-based Semi-hard Synthetic Face Generation (CemiFace)) which produces facial samples with various levels of similarity to the subject center, thus allowing to generate face datasets containing effective discriminative samples for training face recognition. Experimental results show that with a modest degree of similarity, training on the generated dataset can produce competitive performance compared to previous generation methods.