 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAILS-NTUA at SemEval-2026 Task 3: Efficient Dimensional Aspect-Based Sentiment Analysis
Mar 05, 2026In this paper, we present AILS-NTUA system for Track-A of SemEval-2026 Task 3 on Dimensional Aspect-Based Sentiment Analysis (DimABSA), which encompasses three complementary problems: Dimensional Aspect Sentiment Regression (DimASR), Dimensional Aspect Sentiment Triplet Extraction (DimASTE), and Dimensional Aspect Sentiment Quadruplet Prediction (DimASQP) within a multilingual and multi-domain framework. Our methodology combines fine-tuning of language-appropriate encoder backbones for continuous aspect-level sentiment prediction with language-specific instruction tuning of large language models using LoRA for structured triplet and quadruplet extraction. This unified yet task-adaptive design emphasizes parameter-efficient specialization across languages and domains, enabling reduced training and inference requirements while maintaining strong effectiveness. Empirical results demonstrate that the proposed models achieve competitive performance and consistently surpass the provided baselines across most evaluation settings.
Rethinking Affect Analysis: A Protocol for Ensuring Fairness and Consistency
Aug 07, 2024



Evaluating affect analysis methods presents challenges due to inconsistencies in database partitioning and evaluation protocols, leading to unfair and biased results. Previous studies claim continuous performance improvements, but our findings challenge such assertions. Using these insights, we propose a unified protocol for database partitioning that ensures fairness and comparability. We provide detailed demographic annotations (in terms of race, gender and age), evaluation metrics, and a common framework for expression recognition, action unit detection and valence-arousal estimation. We also rerun the methods with the new protocol and introduce a new leaderboards to encourage future research in affect recognition with a fairer comparison. Our annotations, code, and pre-trained models are available on \hyperlink{https://github.com/dkollias/Fair-Consistent-Affect-Analysis}{Github}.
Complex Style Image Transformations for Domain Generalization in Medical Images
Jun 01, 2024



The absence of well-structured large datasets in medical computer vision results in decreased performance of automated systems and, especially, of deep learning models. Domain generalization techniques aim to approach unknown domains from a single data source. In this paper we introduce a novel framework, named CompStyle, which leverages style transfer and adversarial training, along with high-level input complexity augmentation to effectively expand the domain space and address unknown distributions. State-of-the-art style transfer methods depend on the existence of subdomains within the source dataset. However, this can lead to an inherent dataset bias in the image creation. Input-level augmentation can provide a solution to this problem by widening the domain space in the source dataset and boost performance on out-of-domain distributions. We provide results from experiments on semantic segmentation on prostate data and corruption robustness on cardiac data which demonstrate the effectiveness of our approach. Our method increases performance in both tasks, without added cost to training time or resources.
Bridging the Gap: Protocol Towards Fair and Consistent Affect Analysis
May 16, 2024The increasing integration of machine learning algorithms in daily life underscores the critical need for fairness and equity in their deployment. As these technologies play a pivotal role in decision-making, addressing biases across diverse subpopulation groups, including age, gender, and race, becomes paramount. Automatic affect analysis, at the intersection of physiology, psychology, and machine learning, has seen significant development. However, existing databases and methodologies lack uniformity, leading to biased evaluations. This work addresses these issues by analyzing six affective databases, annotating demographic attributes, and proposing a common protocol for database partitioning. Emphasis is placed on fairness in evaluations. Extensive experiments with baseline and state-of-the-art methods demonstrate the impact of these changes, revealing the inadequacy of prior assessments. The findings underscore the importance of considering demographic attributes in affect analysis research and provide a foundation for more equitable methodologies. Our annotations, code and pre-trained models are available at: https://github.com/dkollias/Fair-Consistent-Affect-Analysis
U-Sketch: An Efficient Approach for Sketch to Image Diffusion Models
Mar 27, 2024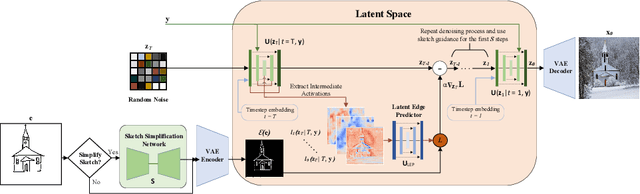
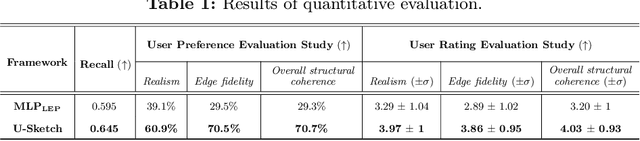

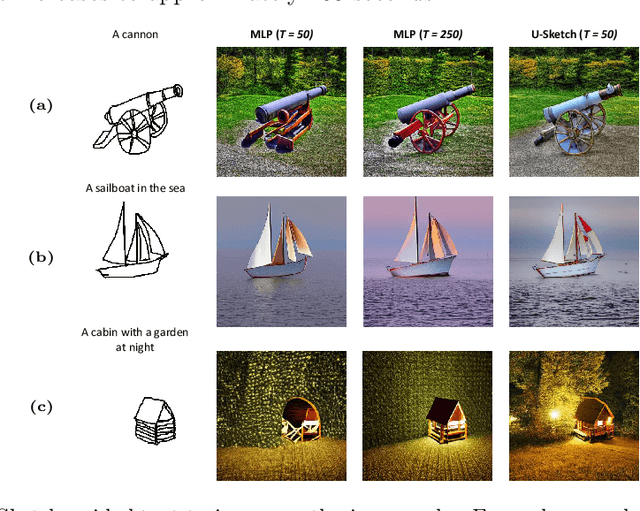
Diffusion models have demonstrated remarkable performance in text-to-image synthesis, producing realistic and high resolution images that faithfully adhere to the corresponding text-prompts. Despite their great success, they still fall behind in sketch-to-image synthesis tasks, where in addition to text-prompts, the spatial layout of the generated images has to closely follow the outlines of certain reference sketches. Employing an MLP latent edge predictor to guide the spatial layout of the synthesized image by predicting edge maps at each denoising step has been recently proposed. Despite yielding promising results, the pixel-wise operation of the MLP does not take into account the spatial layout as a whole, and demands numerous denoising iterations to produce satisfactory images, leading to time inefficiency. To this end, we introduce U-Sketch, a framework featuring a U-Net type latent edge predictor, which is capable of efficiently capturing both local and global features, as well as spatial correlations between pixels. Moreover, we propose the addition of a sketch simplification network that offers the user the choice of preprocessing and simplifying input sketches for enhanced outputs. The experimental results, corroborated by user feedback, demonstrate that our proposed U-Net latent edge predictor leads to more realistic results, that are better aligned with the spatial outlines of the reference sketches, while drastically reducing the number of required denoising steps and, consequently, the overall execution time.
Mitigating Exposure Bias in Discriminator Guided Diffusion Models
Nov 18, 2023Diffusion Models have demonstrated remarkable performance in image generation. However, their demanding computational requirements for training have prompted ongoing efforts to enhance the quality of generated images through modifications in the sampling process. A recent approach, known as Discriminator Guidance, seeks to bridge the gap between the model score and the data score by incorporating an auxiliary term, derived from a discriminator network. We show that despite significantly improving sample quality, this technique has not resolved the persistent issue of Exposure Bias and we propose SEDM-G++, which incorporates a modified sampling approach, combining Discriminator Guidance and Epsilon Scaling. Our proposed approach outperforms the current state-of-the-art, by achieving an FID score of 1.73 on the unconditional CIFAR-10 dataset.