 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-manifold Attention for Vision Transformers
Paper and Code
Jul 18, 2022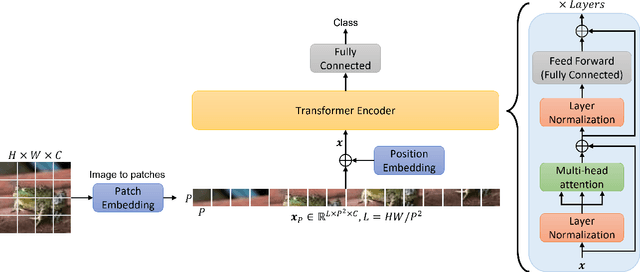

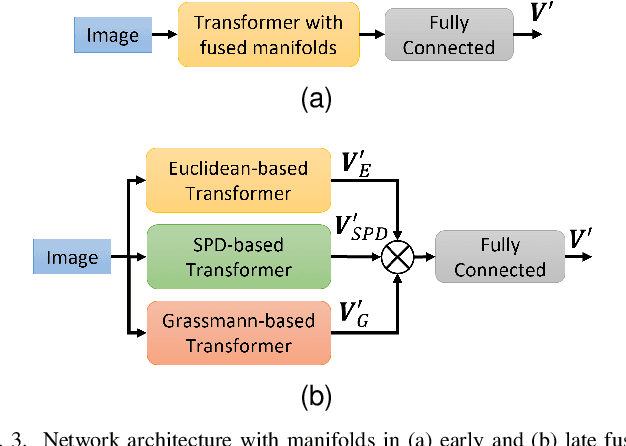

Vision Transformer are very popular nowadays due to their state-of-the-art performance in several computer vision tasks, such as image classification and action recognition. Although the performance of Vision Transformers have been greatly improved by employing Convolutional Neural Networks, hierarchical structures and compact forms, there is limited research on ways to utilize additional data representations to refine the attention map derived from the multi-head attention of a Transformer network. This work proposes a novel attention mechanism, called multi-manifold attention, that can substitute any standard attention mechanism in a Transformer-based network. The proposed attention models the input space in three distinct manifolds, namely Euclidean, Symmetric Positive Definite and Grassmann, with different statistical and geometrical properties, guiding the network to take into consideration a rich set of information that describe the appearance, color and texture of an image, for the computation of a highly descriptive attention map. In this way, a Vision Transformer with the proposed attention is guided to become more attentive towards discriminative features, leading to improved classification results, as shown by the experimental results on several well-known image classification datasets.