 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models Generalize but Not in the Way You Might Think
Mar 12, 2026Standard evaluation metrics suggest that Denoising Diffusion Models based on U-Net or Transformer architectures generalize well in practice. However, as it can be shown that an optimal Diffusion Model fully memorizes the training data, the model error determines generalization. Here, we show that although sufficiently large denoiser models show increasing memorization of the training set with increasing training time, the resulting denoising trajectories do not follow this trend. Our experiments indicate that the reason for this observation is rooted in the fact that overfitting occurs at intermediate noise levels, but the distribution of noisy training data at these noise levels has little overlap with denoising trajectories during inference. To gain more insight, we make use of a 2D toy diffusion model to show that overfitting at intermediate noise levels is largely determined by model error and the density of the data support. While the optimal denoising flow field localizes sharply around training samples, sufficient model error or dense support on the data manifold suppresses exact recall, yielding a smooth, generalizing flow field. To further support our results, we investigate how several factors, such as training time, model size, dataset size, condition granularity, and diffusion guidance, influence generalization behavior.
The Unreasonable Effectiveness of Guidance for Diffusion Models
Nov 15, 2024
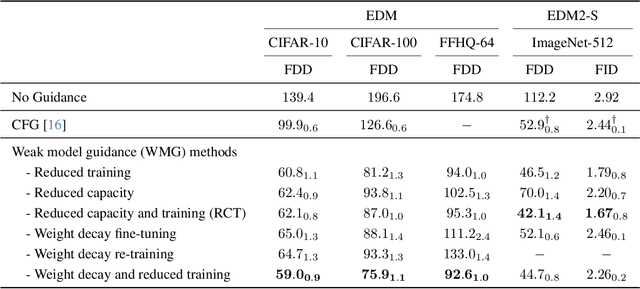
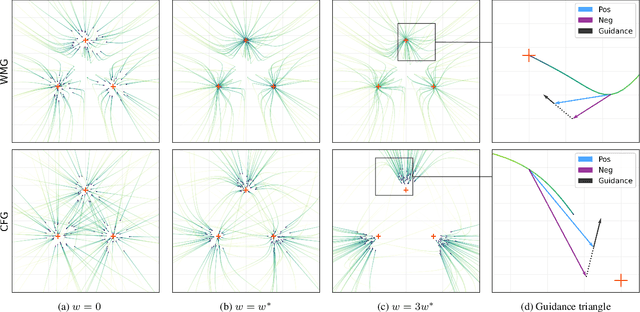
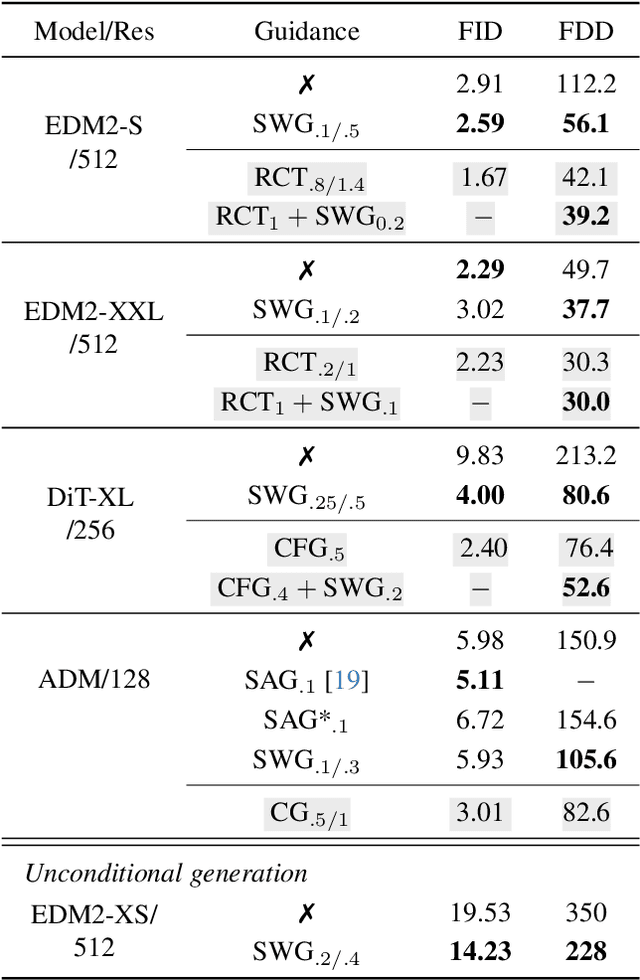
Guidance is an error-correcting technique used to improve the perceptual quality of images generated by diffusion models. Typically, the correction is achieved by linear extrapolation, using an auxiliary diffusion model that has lower performance than the primary model. Using a 2D toy example, we show that it is highly beneficial when the auxiliary model exhibits similar errors as the primary one but stronger. We verify this finding in higher dimensions, where we show that competitive generative performance to state-of-the-art guidance methods can be achieved when the auxiliary model differs from the primary one only by having stronger weight regularization. As an independent contribution, we investigate whether upweighting long-range spatial dependencies improves visual fidelity. The result is a novel guidance method, which we call sliding window guidance (SWG), that guides the primary model with itself by constraining its receptive field. Intriguingly, SWG aligns better with human preferences than state-of-the-art guidance methods while requiring neither training, architectural modifications, nor class conditioning. The code will be released.
Rethinking cluster-conditioned diffusion models
Mar 01, 2024We present a comprehensive experimental study on image-level conditioning for diffusion models using cluster assignments. We elucidate how individual components regarding image clustering impact image synthesis across three datasets. By combining recent advancements from image clustering and diffusion models, we show that, given the optimal cluster granularity with respect to image synthesis (visual groups), cluster-conditioning can achieve state-of-the-art FID (i.e. 1.67, 2.17 on CIFAR10 and CIFAR100 respectively), while attaining a strong training sample efficiency. Finally, we propose a novel method to derive an upper cluster bound that reduces the search space of the visual groups using solely feature-based clustering. Unlike existing approaches, we find no significant connection between clustering and cluster-conditional image generation. The code and cluster assignments will be released.
Contrastive Language-Image Pretrained Models are Powerful Out-of-Distribution Detectors
Mar 10, 2023



We present a comprehensive experimental study on pretrained feature extractors for visual out-of-distribution (OOD) detection. We examine several setups, based on the availability of labels or image captions and using different combinations of in- and out-distributions. Intriguingly, we find that (i) contrastive language-image pretrained models achieve state-of-the-art unsupervised out-of-distribution performance using nearest neighbors feature similarity as the OOD detection score, (ii) supervised state-of-the-art OOD detection performance can be obtained without in-distribution fine-tuning, (iii) even top-performing billion-scale vision transformers trained with natural language supervision fail at detecting adversarially manipulated OOD images. Finally, we argue whether new benchmarks for visual anomaly detection are needed based on our experiments. Using the largest publicly available vision transformer, we achieve state-of-the-art performance across all $18$ reported OOD benchmarks, including an AUROC of 87.6\% (9.2\% gain, unsupervised) and 97.4\% (1.2\% gain, supervised) for the challenging task of CIFAR100 $\rightarrow$ CIFAR10 OOD detection. The code will be open-sourced.