 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Speech Recognition and End-of-Utterance Detection Towards Spoken Dialog Systems
Sep 30, 2024
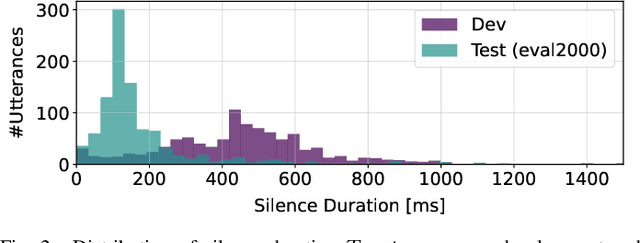
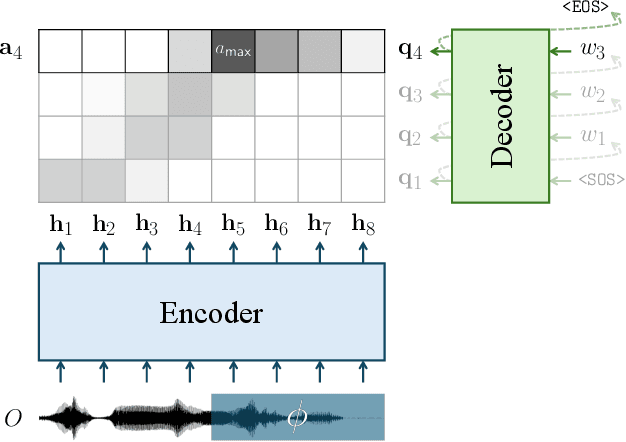
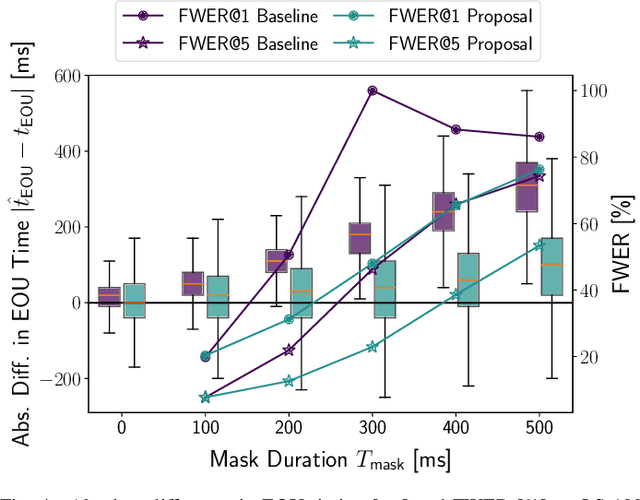
Effective spoken dialog systems should facilitate natural interactions with quick and rhythmic timing, mirroring human communication patterns. To reduce response times, previous efforts have focused on minimizing the latency in automatic speech recognition (ASR) to optimize system efficiency. However, this approach requires waiting for ASR to complete processing until a speaker has finished speaking, which limits the time available for natural language processing (NLP) to formulate accurate responses. As humans, we continuously anticipate and prepare responses even while the other party is still speaking. This allows us to respond appropriately without missing the optimal time to speak. In this work, as a pioneering study toward a conversational system that simulates such human anticipatory behavior, we aim to realize a function that can predict the forthcoming words and estimate the time remaining until the end of an utterance (EOU), using the middle portion of an utterance. To achieve this, we propose a training strategy for an encoder-decoder-based ASR system, which involves masking future segments of an utterance and prompting the decoder to predict the words in the masked audio. Additionally, we develop a cross-attention-based algorithm that incorporates both acoustic and linguistic information to accurately detect the EOU. The experimental results demonstrate the proposed model's ability to predict upcoming words and estimate future EOU events up to 300ms prior to the actual EOU. Moreover, the proposed training strategy exhibits general improvements in ASR performance.