 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBimodal Speech Emotion Recognition Using Pre-Trained Language Models
Paper and Code
Nov 29, 2019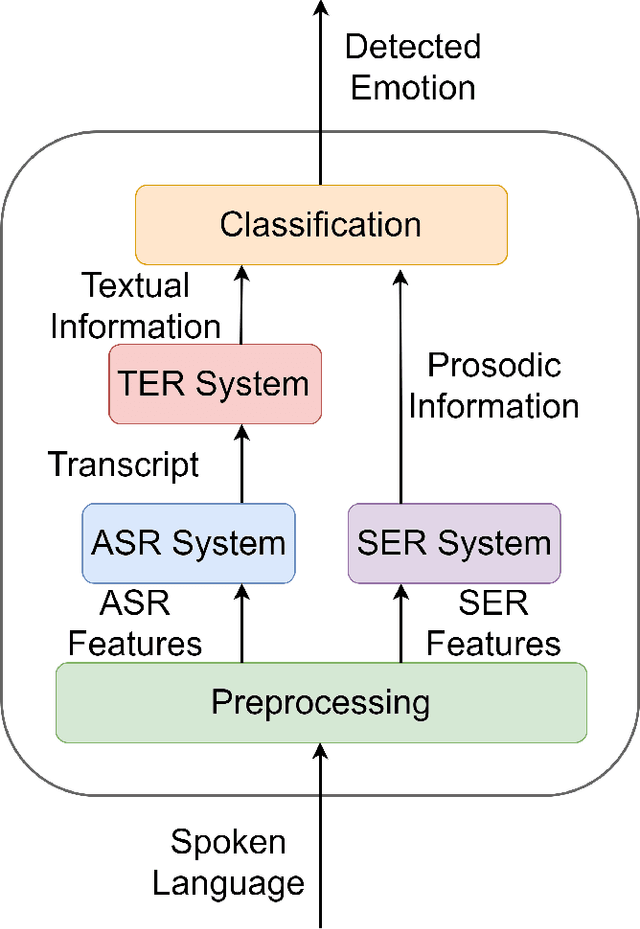
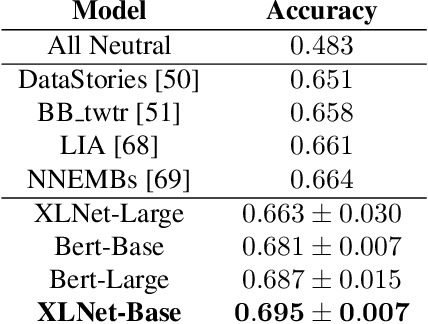

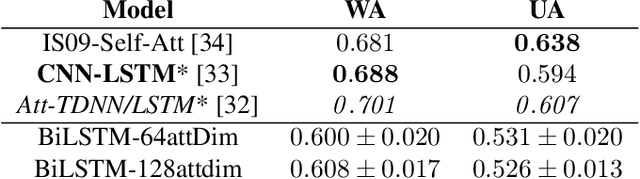
Speech emotion recognition is a challenging task and an important step towards more natural human-machine interaction. We show that pre-trained language models can be fine-tuned for text emotion recognition, achieving an accuracy of 69.5% on Task 4A of SemEval 2017, improving upon the previous state of the art by over 3% absolute. We combine these language models with speech emotion recognition, achieving results of 73.5% accuracy when using provided transcriptions and speech data on a subset of four classes of the IEMOCAP dataset. The use of noise-induced transcriptions and speech data results in an accuracy of 71.4%. For our experiments, we created IEmoNet, a modular and adaptable bimodal framework for speech emotion recognition based on pre-trained language models. Lastly, we discuss the idea of using an emotional classifier as a reward for reinforcement learning as a step towards more successful and convenient human-machine interaction.