 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAIS ASR: Building a conversational speech recognition system using language model combination
Paper and Code
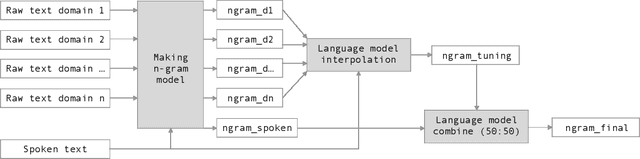

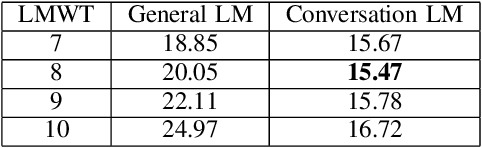
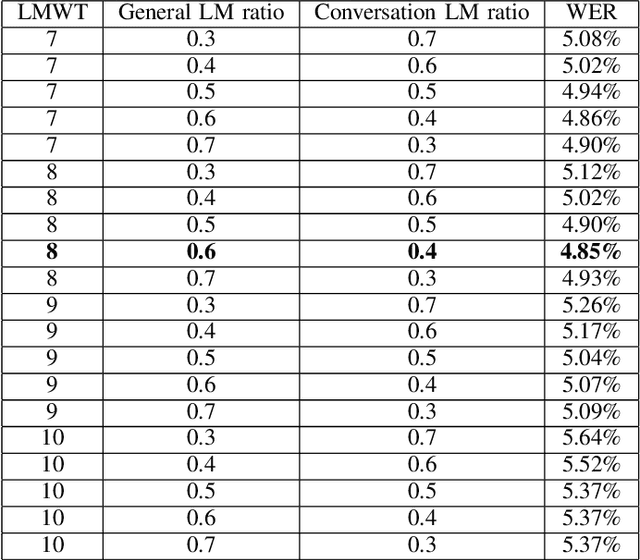
Automatic Speech Recognition (ASR) systems have been evolving quickly and reaching human parity in certain cases. The systems usually perform pretty well on reading style and clean speech, however, most of the available systems suffer from situation where the speaking style is conversation and in noisy environments. It is not straight-forward to tackle such problems due to difficulties in data collection for both speech and text. In this paper, we attempt to mitigate the problems using language models combination techniques that allows us to utilize both large amount of writing style text and small number of conversation text data. Evaluation on the VLSP 2019 ASR challenges showed that our system achieved 4.85% WER on the VLSP 2018 and 15.09% WER on the VLSP 2019 data sets.