 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Vietnamese Named Entity Recognition from Speech Using Word Capitalization and Punctuation Recovery Models
Paper and Code
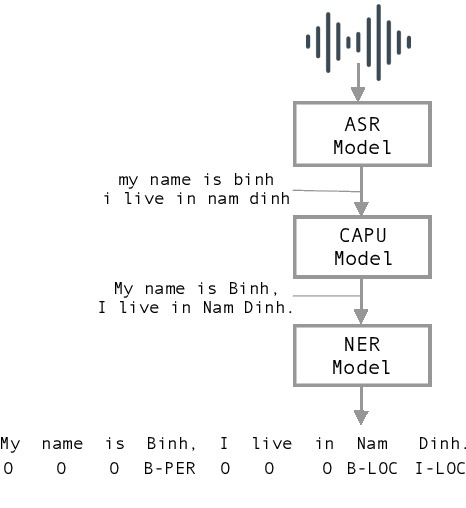

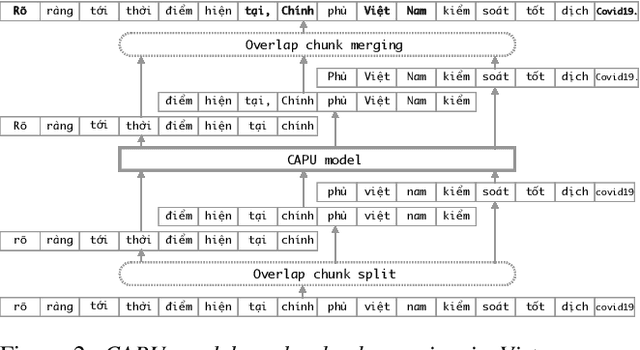
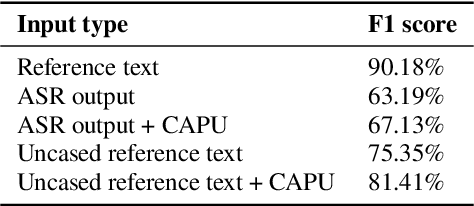
Studies on the Named Entity Recognition (NER) task have shown outstanding results that reach human parity on input texts with correct text formattings, such as with proper punctuation and capitalization. However, such conditions are not available in applications where the input is speech, because the text is generated from a speech recognition system (ASR), and that the system does not consider the text formatting. In this paper, we (1) presented the first Vietnamese speech dataset for NER task, and (2) the first pre-trained public large-scale monolingual language model for Vietnamese that achieved the new state-of-the-art for the Vietnamese NER task by 1.3% absolute F1 score comparing to the latest study. And finally, (3) we proposed a new pipeline for NER task from speech that overcomes the text formatting problem by introducing a text capitalization and punctuation recovery model (CaPu) into the pipeline. The model takes input text from an ASR system and performs two tasks at the same time, producing proper text formatting that helps to improve NER performance. Experimental results indicated that the CaPu model helps to improve by nearly 4% of F1-score.