 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Machine Collaborative Video Coding Through Cuboidal Partitioning
Feb 02, 2021


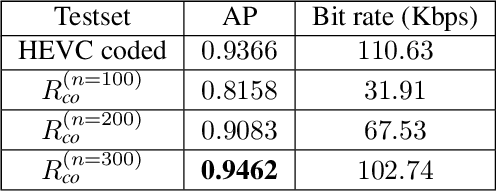
Video coding algorithms encode and decode an entire video frame while feature coding techniques only preserve and communicate the most critical information needed for a given application. This is because video coding targets human perception, while feature coding aims for machine vision tasks. Recently, attempts are being made to bridge the gap between these two domains. In this work, we propose a video coding framework by leveraging on to the commonality that exists between human vision and machine vision applications using cuboids. This is because cuboids, estimated rectangular regions over a video frame, are computationally efficient, has a compact representation and object centric. Such properties are already shown to add value to traditional video coding systems. Herein cuboidal feature descriptors are extracted from the current frame and then employed for accomplishing a machine vision task in the form of object detection. Experimental results show that a trained classifier yields superior average precision when equipped with cuboidal features oriented representation of the current test frame. Additionally, this representation costs 7% less in bit rate if the captured frames are need be communicated to a receiver.