 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Report for Egocentric Mistake Detection for the HoloAssist Challenge
Jun 06, 2025



In this report, we address the task of online mistake detection, which is vital in domains like industrial automation and education, where real-time video analysis allows human operators to correct errors as they occur. While previous work focuses on procedural errors involving action order, broader error types must be addressed for real-world use. We introduce an online mistake detection framework that handles both procedural and execution errors (e.g., motor slips or tool misuse). Upon detecting an error, we use a large language model (LLM) to generate explanatory feedback. Experiments on the HoloAssist benchmark confirm the effectiveness of our approach, where our approach is placed second on the mistake detection task.
ADL4D: Towards A Contextually Rich Dataset for 4D Activities of Daily Living
Feb 27, 2024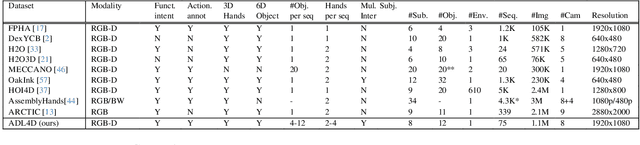



Hand-Object Interactions (HOIs) are conditioned on spatial and temporal contexts like surrounding objects, pre- vious actions, and future intents (for example, grasping and handover actions vary greatly based on objects proximity and trajectory obstruction). However, existing datasets for 4D HOI (3D HOI over time) are limited to one subject inter- acting with one object only. This restricts the generalization of learning-based HOI methods trained on those datasets. We introduce ADL4D, a dataset of up to two subjects inter- acting with different sets of objects performing Activities of Daily Living (ADL) like breakfast or lunch preparation ac- tivities. The transition between multiple objects to complete a certain task over time introduces a unique context lacking in existing datasets. Our dataset consists of 75 sequences with a total of 1.1M RGB-D frames, hand and object poses, and per-hand fine-grained action annotations. We develop an automatic system for multi-view multi-hand 3D pose an- notation capable of tracking hand poses over time. We inte- grate and test it against publicly available datasets. Finally, we evaluate our dataset on the tasks of Hand Mesh Recov- ery (HMR) and Hand Action Segmentation (HAS).