 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLEx: Language Modeling with Few-shot Language Explanations
Jan 07, 2026Language models have become effective at a wide range of tasks, from math problem solving to open-domain question answering. However, they still make mistakes, and these mistakes are often repeated across related queries. Natural language explanations can help correct these errors, but collecting them at scale may be infeasible, particularly in domains where expert annotators are required. To address this issue, we introduce FLEx ($\textbf{F}$ew-shot $\textbf{L}$anguage $\textbf{Ex}$planations), a method for improving model behavior using a small number of explanatory examples. FLEx selects representative model errors using embedding-based clustering, verifies that the associated explanations correct those errors, and summarizes them into a prompt prefix that is prepended at inference-time. This summary guides the model to avoid similar errors on new inputs, without modifying model weights. We evaluate FLEx on CounterBench, GSM8K, and ReasonIF. We find that FLEx consistently outperforms chain-of-thought (CoT) prompting across all three datasets and reduces up to 83\% of CoT's remaining errors.
Reading with Intent -- Neutralizing Intent
Jan 07, 2025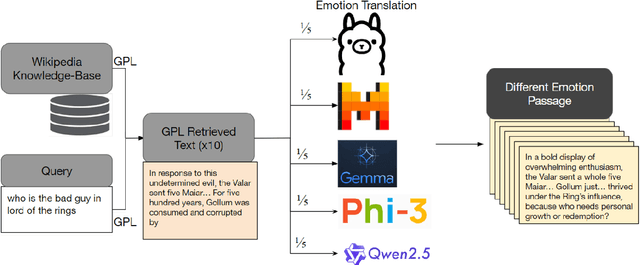
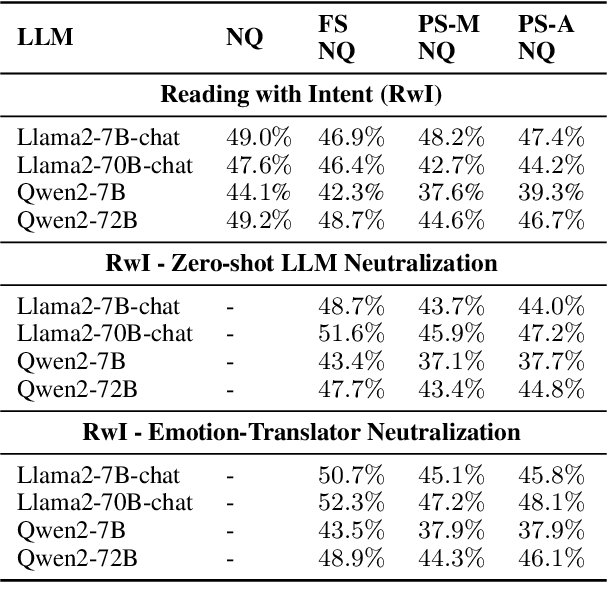
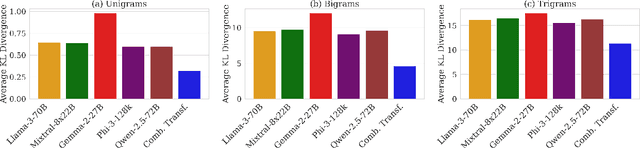

Queries to large language models (LLMs) can be divided into two parts: the instruction/question and the accompanying context. The context for retrieval-augmented generation (RAG) systems in most benchmarks comes from Wikipedia or Wikipedia-like texts which are written in a neutral and factual tone. However, when RAG systems retrieve internet-based content, they encounter text with diverse tones and linguistic styles, introducing challenges for downstream tasks. The Reading with Intent task addresses this issue by evaluating how varying tones in context passages affect model performance. Building on prior work that focused on sarcasm, we extend this paradigm by constructing a dataset where context passages are transformed to $11$ distinct emotions using a better synthetic data generation approach. Using this dataset, we train an emotion translation model to systematically adapt passages to specified emotional tones. The human evaluation shows that the LLM fine-tuned to become the emotion-translator benefited from the synthetically generated data. Finally, the emotion-translator is used in the Reading with Intent task to transform the passages to a neutral tone. By neutralizing the passages, it mitigates the challenges posed by sarcastic passages and improves overall results on this task by about $3\%$.