 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALE: Online Self-Supervised Lifelong Learning without Prior Knowledge
Paper and Code
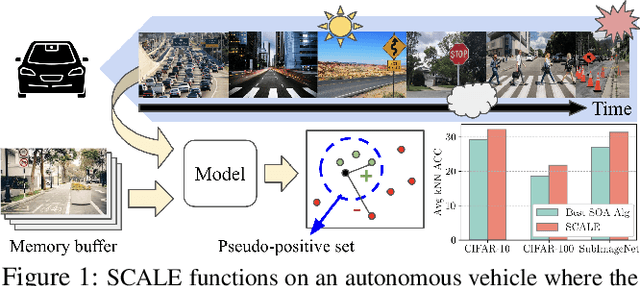
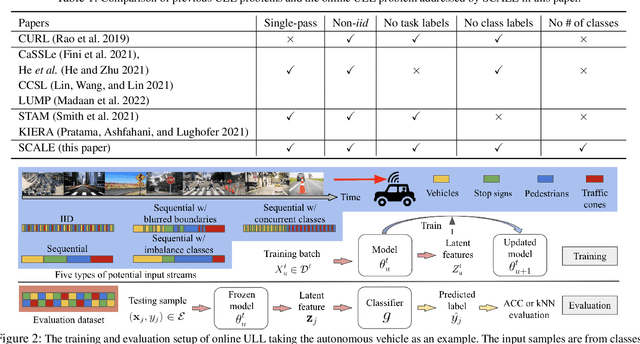
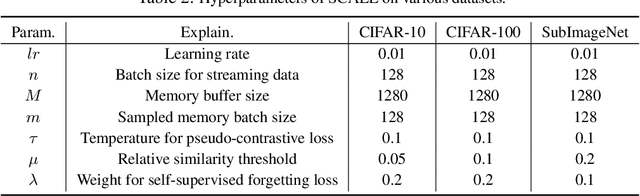
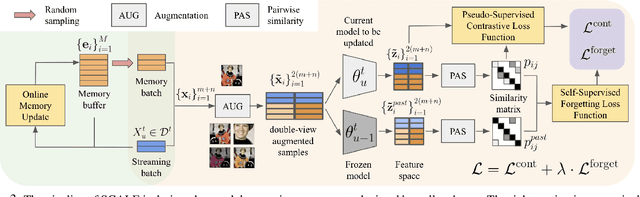
Unsupervised lifelong learning refers to the ability to learn over time while memorizing previous patterns without supervision. Previous works assumed strong prior knowledge about the incoming data (e.g., knowing the class boundaries) which can be impossible to obtain in complex and unpredictable environments. In this paper, motivated by real-world scenarios, we formally define the online unsupervised lifelong learning problem with class-incremental streaming data, which is non-iid and single-pass. The problem is more challenging than existing lifelong learning problems due to the absence of labels and prior knowledge. To address the issue, we propose Self-Supervised ContrAstive Lifelong LEarning (SCALE) which extracts and memorizes knowledge on-the-fly. SCALE is designed around three major components: a pseudo-supervised contrastive loss, a self-supervised forgetting loss, and an online memory update for uniform subset selection. All three components are designed to work collaboratively to maximize learning performance. Our loss functions leverage pairwise similarity thus remove the dependency on supervision or prior knowledge. We perform comprehensive experiments of SCALE under iid and four non-iid data streams. SCALE outperforms the best state-of-the-art algorithm on all settings with improvements of up to 6.43%, 5.23% and 5.86% kNN accuracy on CIFAR-10, CIFAR-100 and SubImageNet datasets.