 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProceedings of the Sixth Conference on Uncertainty in Artificial Intelligence (1990)
Aug 28, 2014This is the Proceedings of the Sixth Conference on Uncertainty in Artificial Intelligence, which was held in Cambridge, MA, Jul 27 - Jul 29, 1990
Proceedings of the Fifth Conference on Uncertainty in Artificial Intelligence (1989)
Apr 13, 2013This is the Proceedings of the Fifth Conference on Uncertainty in Artificial Intelligence, which was held in Windsor, ON, August 18-20, 1989
A Framework for Comparing Uncertain Inference Systems to Probability
Mar 27, 2013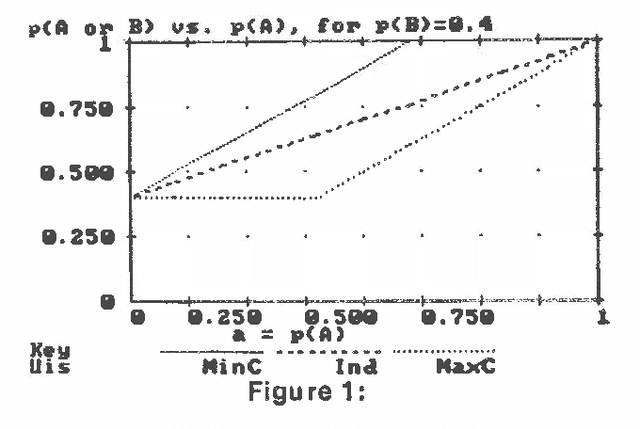
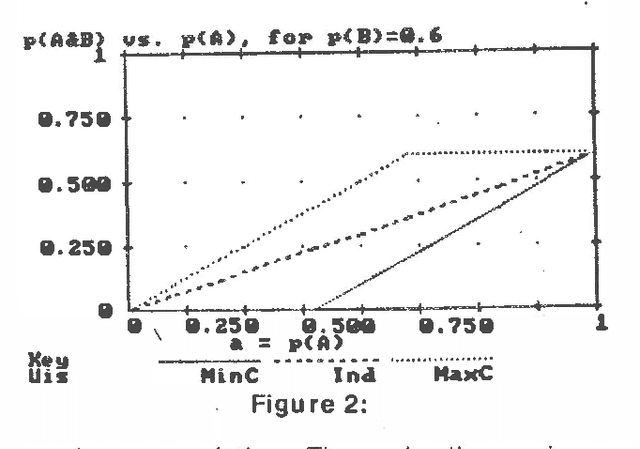
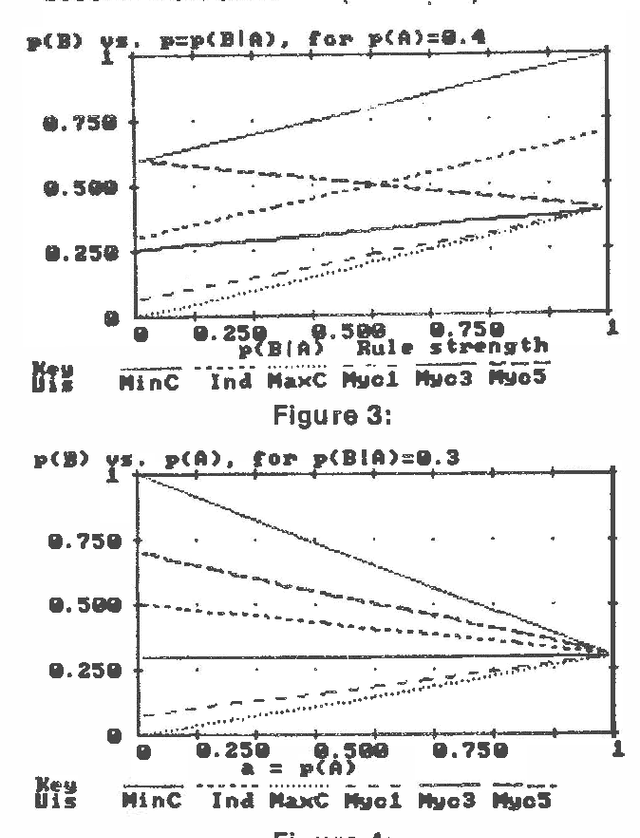
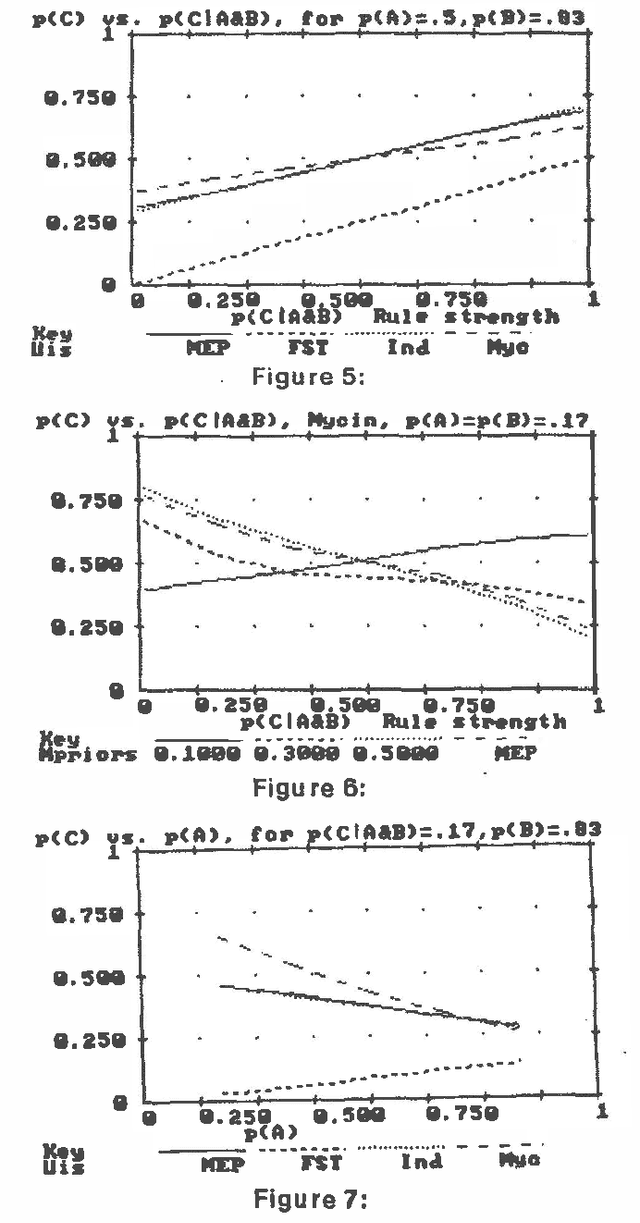
Several different uncertain inference systems (UISs) have been developed for representing uncertainty in rule-based expert systems. Some of these, such as Mycin's Certainty Factors, Prospector, and Bayes' Networks were designed as approximations to probability, and others, such as Fuzzy Set Theory and DempsterShafer Belief Functions were not. How different are these UISs in practice, and does it matter which you use? When combining and propagating uncertain information, each UIS must, at least by implication, make certain assumptions about correlations not explicily specified. The maximum entropy principle with minimum cross-entropy updating, provides a way of making assumptions about the missing specification that minimizes the additional information assumed, and thus offers a standard against which the other UISs can be compared. We describe a framework for the experimental comparison of the performance of different UISs, and provide some illustrative results.
Practical Issues in Constructing a Bayes' Belief Network
Mar 27, 2013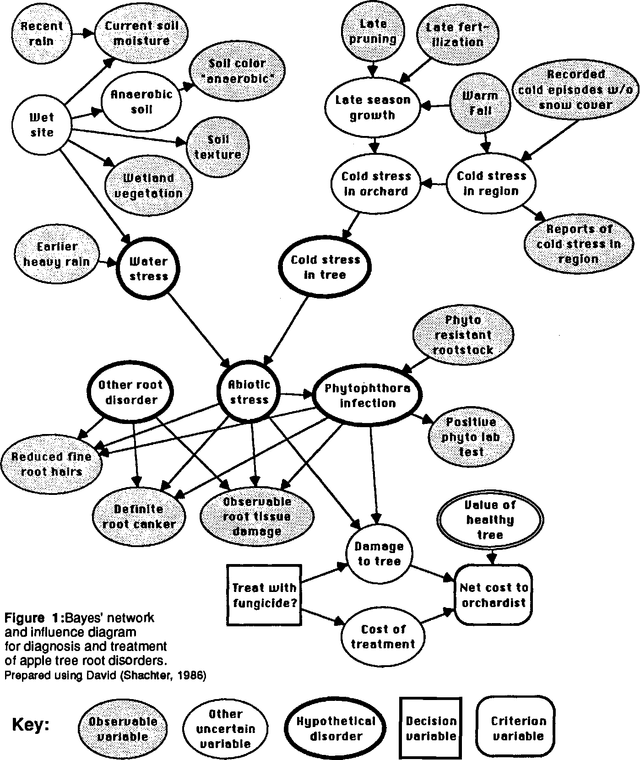

Bayes belief networks and influence diagrams are tools for constructing coherent probabilistic representations of uncertain knowledge. The process of constructing such a network to represent an expert's knowledge is used to illustrate a variety of techniques which can facilitate the process of structuring and quantifying uncertain relationships. These include some generalizations of the "noisy OR gate" concept. Sensitivity analysis of generic elements of Bayes' networks provides insight into when rough probability assessments are sufficient and when greater precision may be important.
A Comparison of Decision Analysis and Expert Rules for Sequential Diagnosis
Mar 27, 2013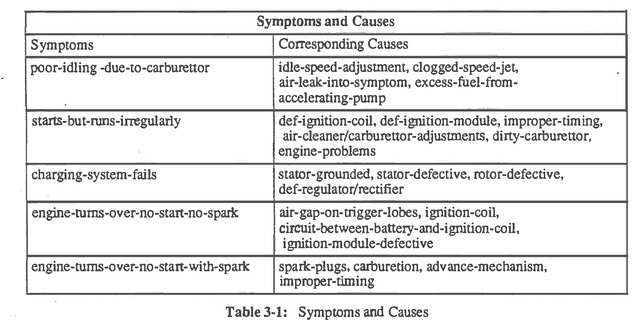
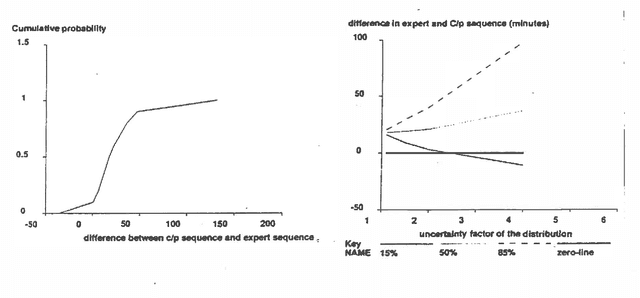
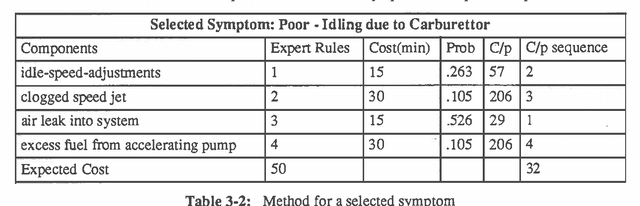

There has long been debate about the relative merits of decision theoretic methods and heuristic rule-based approaches for reasoning under uncertainty. We report an experimental comparison of the performance of the two approaches to troubleshooting, specifically to test selection for fault diagnosis. We use as experimental testbed the problem of diagnosing motorcycle engines. The first approach employs heuristic test selection rules obtained from expert mechanics. We compare it with the optimal decision analytic algorithm for test selection which employs estimated component failure probabilities and test costs. The decision analytic algorithm was found to reduce the expected cost (i.e. time) to arrive at a diagnosis by an average of 14% relative to the expert rules. Sensitivity analysis shows the results are quite robust to inaccuracy in the probability and cost estimates. This difference suggests some interesting implications for knowledge acquisition.
How Much More Probable is "Much More Probable"? Verbal Expressions for Probability Updates
Mar 27, 2013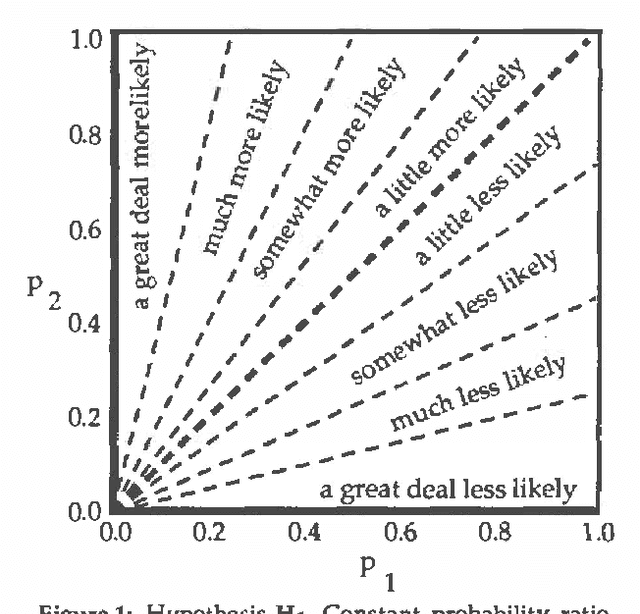
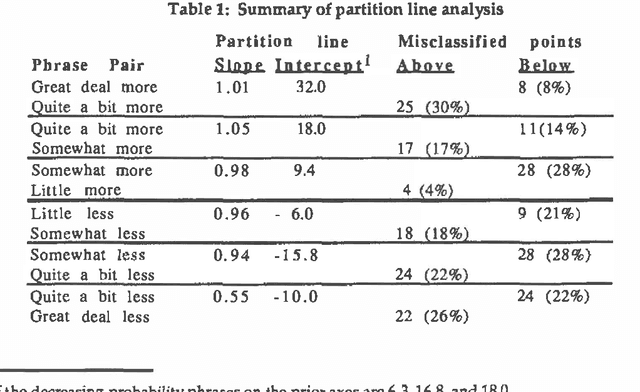
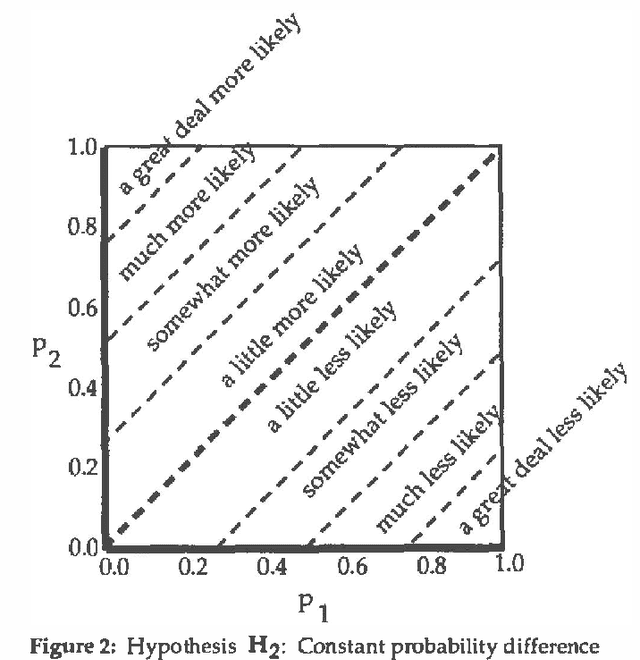
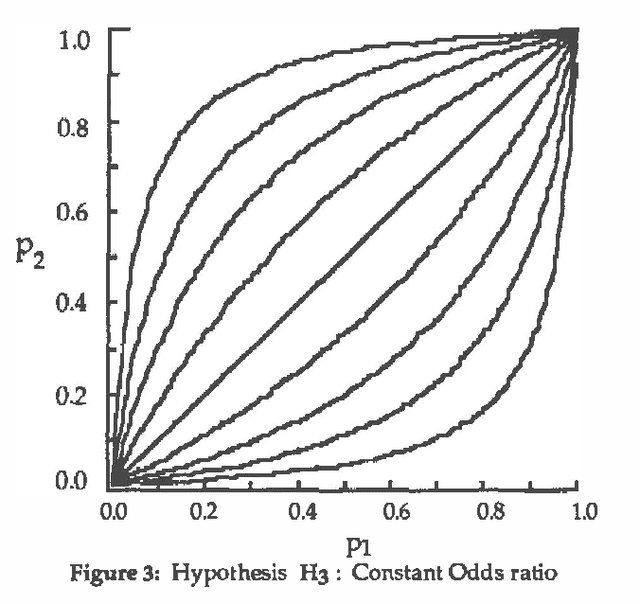
Bayesian inference systems should be able to explain their reasoning to users, translating from numerical to natural language. Previous empirical work has investigated the correspondence between absolute probabilities and linguistic phrases. This study extends that work to the correspondence between changes in probabilities (updates) and relative probability phrases, such as "much more likely" or "a little less likely." Subjects selected such phrases to best describe numerical probability updates. We examined three hypotheses about the correspondence, and found the most descriptively accurate of these three to be that each such phrase corresponds to a fixed difference in probability (rather than fixed ratio of probabilities or of odds). The empirically derived phrase selection function uses eight phrases and achieved a 72% accuracy in correspondence with the subjects' actual usage.
Qualitative Propagation and Scenario-based Explanation of Probabilistic Reasoning
Mar 27, 2013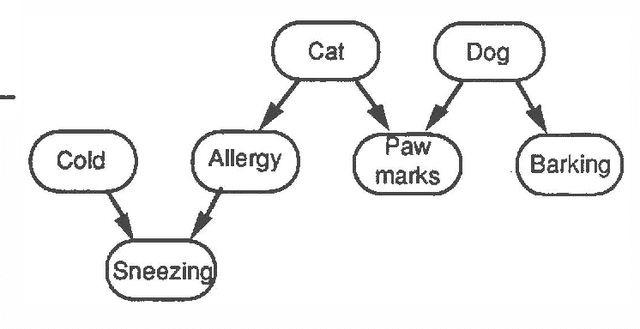


Comprehensible explanations of probabilistic reasoning are a prerequisite for wider acceptance of Bayesian methods in expert systems and decision support systems. A study of human reasoning under uncertainty suggests two different strategies for explaining probabilistic reasoning: The first, qualitative belief propagation, traces the qualitative effect of evidence through a belief network from one variable to the next. This propagation algorithm is an alternative to the graph reduction algorithms of Wellman (1988) for inference in qualitative probabilistic networks. It is based on a qualitative analysis of intercausal reasoning, which is a generalization of Pearl's "explaining away", and an alternative to Wellman's definition of qualitative synergy. The other, Scenario-based reasoning, involves the generation of alternative causal "stories" accounting for the evidence. Comparing a few of the most probable scenarios provides an approximate way to explain the results of probabilistic reasoning. Both schemes employ causal as well as probabilistic knowledge. Probabilities may be presented as phrases and/or numbers. Users can control the style, abstraction and completeness of explanations.
Search-based Methods to Bound Diagnostic Probabilities in Very Large Belief Nets
Mar 20, 2013


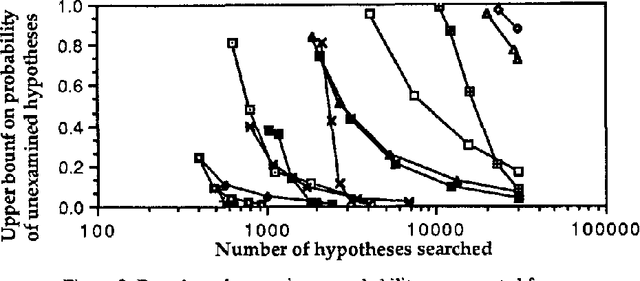
Since exact probabilistic inference is intractable in general for large multiply connected belief nets, approximate methods are required. A promising approach is to use heuristic search among hypotheses (instantiations of the network) to find the most probable ones, as in the TopN algorithm. Search is based on the relative probabilities of hypotheses which are efficient to compute. Given upper and lower bounds on the relative probability of partial hypotheses, it is possible to obtain bounds on the absolute probabilities of hypotheses. Best-first search aimed at reducing the maximum error progressively narrows the bounds as more hypotheses are examined. Here, qualitative probabilistic analysis is employed to obtain bounds on the relative probability of partial hypotheses for the BN20 class of networks networks and a generalization replacing the noisy OR assumption by negative synergy. The approach is illustrated by application to a very large belief network, QMR-BN, which is a reformulation of the Internist-1 system for diagnosis in internal medicine.
Intercausal Reasoning with Uninstantiated Ancestor Nodes
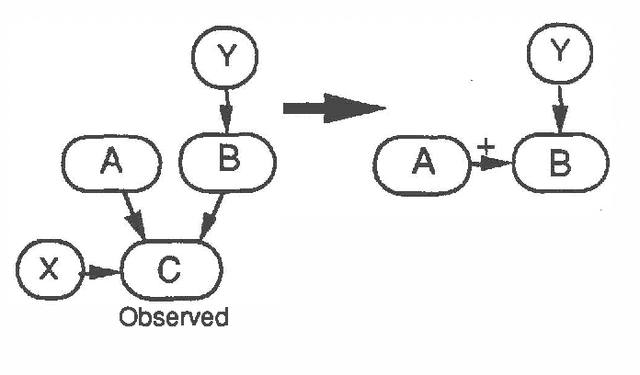
Mar 06, 2013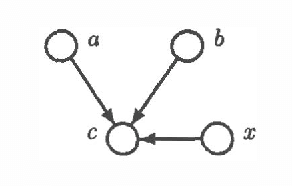
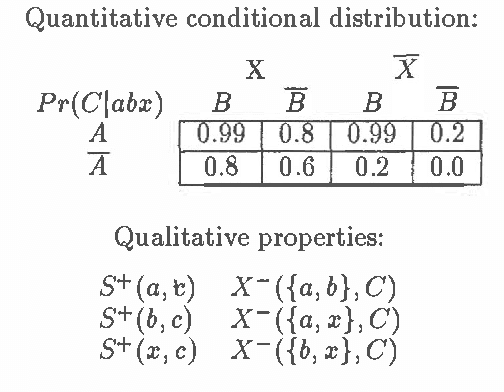
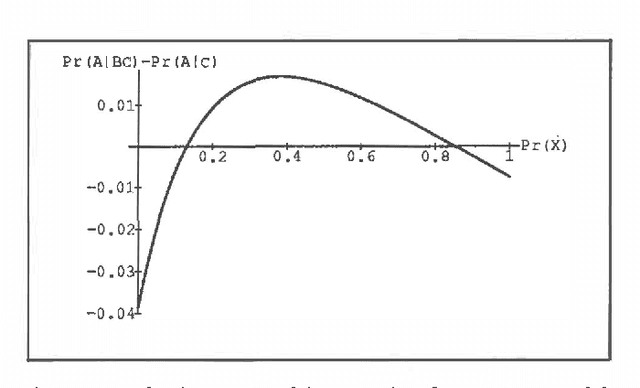
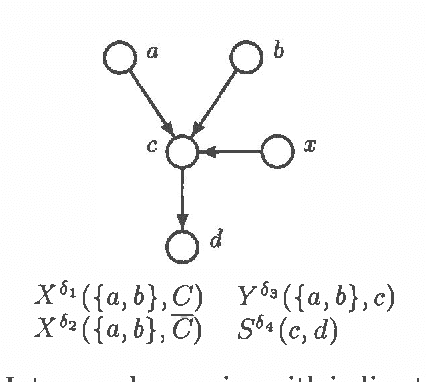
Intercausal reasoning is a common inference pattern involving probabilistic dependence of causes of an observed common effect. The sign of this dependence is captured by a qualitative property called product synergy. The current definition of product synergy is insufficient for intercausal reasoning where there are additional uninstantiated causes of the common effect. We propose a new definition of product synergy and prove its adequacy for intercausal reasoning with direct and indirect evidence for the common effect. The new definition is based on a new property matrix half positive semi-definiteness, a weakened form of matrix positive semi-definiteness.
Knowledge Engineering for Large Belief Networks
Feb 27, 2013

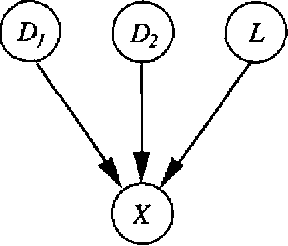

We present several techniques for knowledge engineering of large belief networks (BNs) based on the our experiences with a network derived from a large medical knowledge base. The noisyMAX, a generalization of the noisy-OR gate, is used to model causal in dependence in a BN with multi-valued variables. We describe the use of leak probabilities to enforce the closed-world assumption in our model. We present Netview, a visualization tool based on causal independence and the use of leak probabilities. The Netview software allows knowledge engineers to dynamically view sub-networks for knowledge engineering, and it provides version control for editing a BN. Netview generates sub-networks in which leak probabilities are dynamically updated to reflect the missing portions of the network.