 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Engineering for Large Belief Networks
Feb 27, 2013

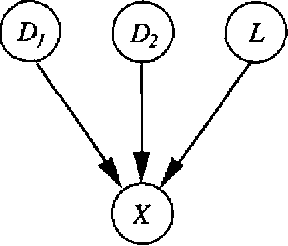

We present several techniques for knowledge engineering of large belief networks (BNs) based on the our experiences with a network derived from a large medical knowledge base. The noisyMAX, a generalization of the noisy-OR gate, is used to model causal in dependence in a BN with multi-valued variables. We describe the use of leak probabilities to enforce the closed-world assumption in our model. We present Netview, a visualization tool based on causal independence and the use of leak probabilities. The Netview software allows knowledge engineers to dynamically view sub-networks for knowledge engineering, and it provides version control for editing a BN. Netview generates sub-networks in which leak probabilities are dynamically updated to reflect the missing portions of the network.
Optimal Monte Carlo Estimation of Belief Network Inference
Feb 13, 2013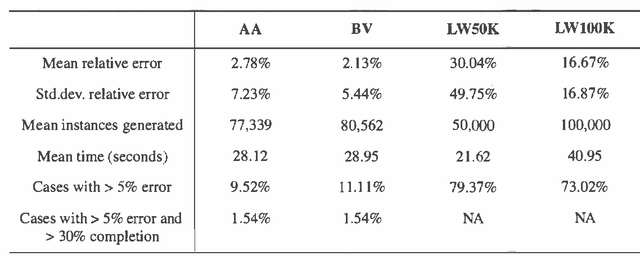
We present two Monte Carlo sampling algorithms for probabilistic inference that guarantee polynomial-time convergence for a larger class of network than current sampling algorithms provide. These new methods are variants of the known likelihood weighting algorithm. We use of recent advances in the theory of optimal stopping rules for Monte Carlo simulation to obtain an inference approximation with relative error epsilon and a small failure probability delta. We present an empirical evaluation of the algorithms which demonstrates their improved performance.
Why Is Diagnosis Using Belief Networks Insensitive to Imprecision In Probabilities?
Feb 13, 2013
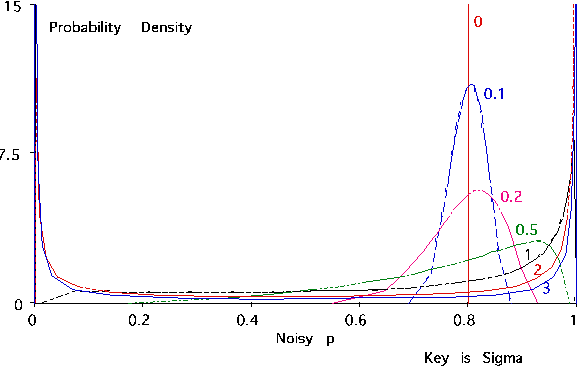
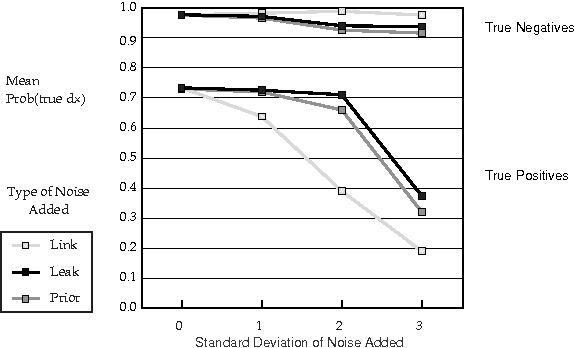
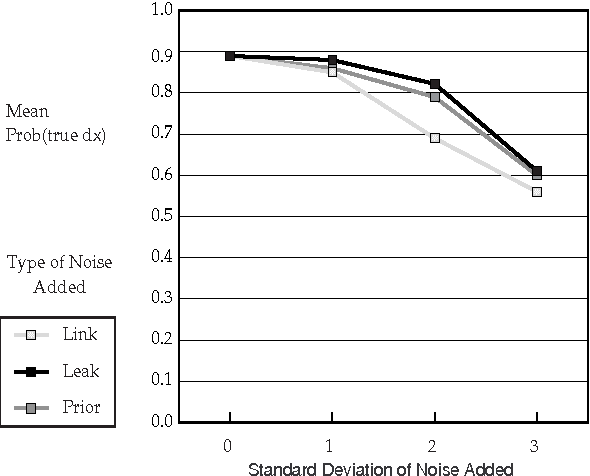
Recent research has found that diagnostic performance with Bayesian belief networks is often surprisingly insensitive to imprecision in the numerical probabilities. For example, the authors have recently completed an extensive study in which they applied random noise to the numerical probabilities in a set of belief networks for medical diagnosis, subsets of the CPCS network, a subset of the QMR (Quick Medical Reference) focused on liver and bile diseases. The diagnostic performance in terms of the average probabilities assigned to the actual diseases showed small sensitivity even to large amounts of noise. In this paper, we summarize the findings of this study and discuss possible explanations of this low sensitivity. One reason is that the criterion for performance is average probability of the true hypotheses, rather than average error in probability, which is insensitive to symmetric noise distributions. But, we show that even asymmetric, logodds-normal noise has modest effects. A second reason is that the gold-standard posterior probabilities are often near zero or one, and are little disturbed by noise.