 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Predictive Coding using Convolutional Neural Networks towards Unsupervised Learning of Speaker Characteristics
Paper and Code
Feb 22, 2018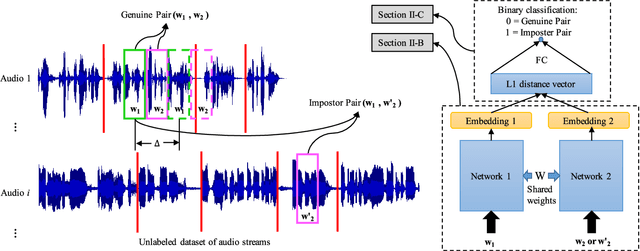
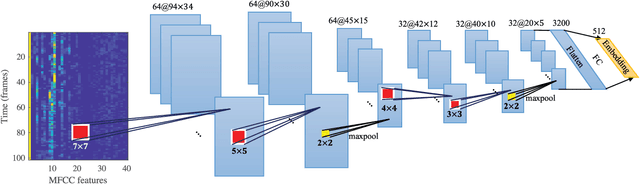
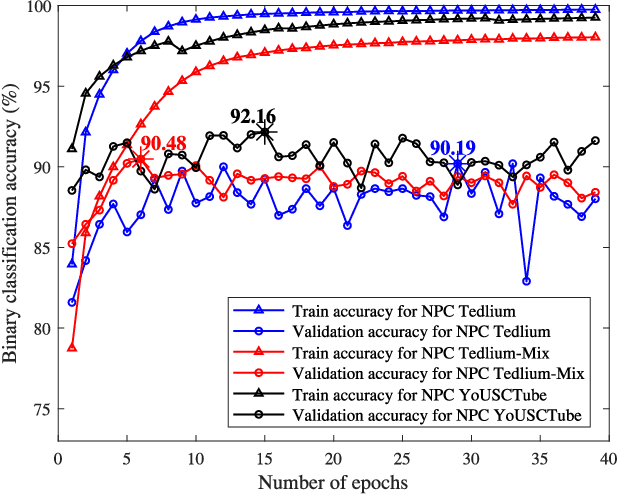
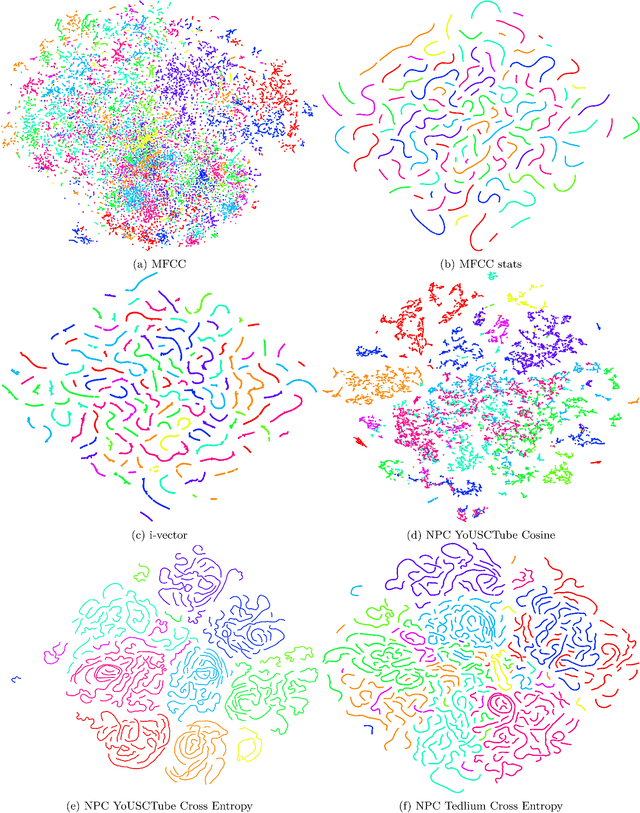
Learning speaker-specific features is vital in many applications like speaker recognition, diarization and speech recognition. This paper provides a novel approach, we term Neural Predictive Coding (NPC), to learn speaker-specific characteristics in a completely unsupervised manner from large amounts of unlabeled training data that even contain multi-speaker audio streams. The NPC framework exploits the proposed short-term active-speaker stationarity hypothesis which assumes two temporally-close short speech segments belong to the same speaker, and thus a common representation that can encode the commonalities of both the segments, should capture the vocal characteristics of that speaker. We train a convolutional deep siamese network to produce "speaker embeddings" by optimizing a loss function that increases between-speaker variability and decreases within-speaker variability. The trained NPC model can produce these embeddings by projecting any test audio stream into a high dimensional manifold where speech frames of the same speaker come closer than they do in the raw feature space. Results in the frame-level speaker classification experiment along with the visualization of the embeddings manifest the distinctive ability of the NPC model to learn short-term speaker-specific features as compared to raw MFCC features and i-vectors. The utterance-level speaker classification experiments show that concatenating simple statistics of the short-term NPC embeddings over the whole utterance with the utterance-level i-vectors can give useful complimentary information to the i-vectors and boost the classification accuracy. The results also show the efficacy of this technique to learn those characteristics from large amounts of unlabeled training set which has no prior information about the environment of the test set.