 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing dynamically varying acoustic scenes from egocentric audio recordings in workplace setting
Nov 10, 2019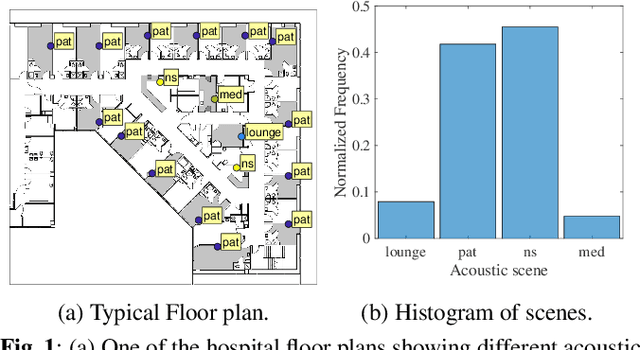



Devices capable of detecting and categorizing acoustic scenes have numerous applications such as providing context-aware user experiences. In this paper, we address the task of characterizing acoustic scenes in a workplace setting from audio recordings collected with wearable microphones. The acoustic scenes, tracked with Bluetooth transceivers, vary dynamically with time from the egocentric perspective of a mobile user. Our dataset contains experience sampled long audio recordings collected from clinical providers in a hospital, who wore the audio badges during multiple work shifts. To handle the long egocentric recordings, we propose a Time Delay Neural Network~(TDNN)-based segment-level modeling. The experiments show that TDNN outperforms other models in the acoustic scene classification task. We investigate the effect of primary speaker's speech in determining acoustic scenes from audio badges, and provide a comparison between performance of different models. Moreover, we explore the relationship between the sequence of acoustic scenes experienced by the users and the nature of their jobs, and find that the scene sequence predicted by our model tend to possess similar relationship. The initial promising results reveal numerous research directions for acoustic scene classification via wearable devices as well as egocentric analysis of dynamic acoustic scenes encountered by the users.