Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactors of Influence of the Overestimation Bias of Q-Learning
Oct 11, 2022

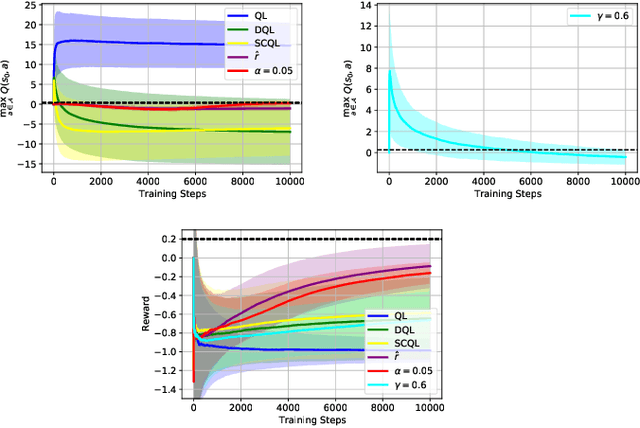

We study whether the learning rate $\alpha$, the discount factor $\gamma$ and the reward signal $r$ have an influence on the overestimation bias of the Q-Learning algorithm. Our preliminary results in environments which are stochastic and that require the use of neural networks as function approximators, show that all three parameters influence overestimation significantly. By carefully tuning $\alpha$ and $\gamma$, and by using an exponential moving average of $r$ in Q-Learning's temporal difference target, we show that the algorithm can learn value estimates that are more accurate than the ones of several other popular model-free methods that have addressed its overestimation bias in the past.
Via