 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Agentic AI Framework for Training General Practitioner Student Skills
Dec 20, 2025



Advancements in large language models offer strong potential for enhancing virtual simulated patients (VSPs) in medical education by providing scalable alternatives to resource-intensive traditional methods. However, current VSPs often struggle with medical accuracy, consistent roleplaying, scenario generation for VSP use, and educationally structured feedback. We introduce an agentic framework for training general practitioner student skills that unifies (i) configurable, evidence-based vignette generation, (ii) controlled persona-driven patient dialogue with optional retrieval grounding, and (iii) standards-based assessment and feedback for both communication and clinical reasoning. We instantiate the framework in an interactive spoken consultation setting and evaluate it with medical students ($\mathbf{N{=}14}$). Participants reported realistic and vignette-faithful dialogue, appropriate difficulty calibration, a stable personality signal, and highly useful example-rich feedback, alongside excellent overall usability. These results support agentic separation of scenario control, interaction control, and standards-based assessment as a practical pattern for building dependable and pedagogically valuable VSP training tools.
Gender Bias in English-to-Greek Machine Translation
Jun 11, 2025As the demand for inclusive language increases, concern has grown over the susceptibility of machine translation (MT) systems to reinforce gender stereotypes. This study investigates gender bias in two commercial MT systems, Google Translate and DeepL, focusing on the understudied English-to-Greek language pair. We address three aspects of gender bias: i) male bias, ii) occupational stereotyping, and iii) errors in anti-stereotypical translations. Additionally, we explore the potential of prompted GPT-4o as a bias mitigation tool that provides both gender-explicit and gender-neutral alternatives when necessary. To achieve this, we introduce GendEL, a manually crafted bilingual dataset of 240 gender-ambiguous and unambiguous sentences that feature stereotypical occupational nouns and adjectives. We find persistent gender bias in translations by both MT systems; while they perform well in cases where gender is explicitly defined, with DeepL outperforming both Google Translate and GPT-4o in feminine gender-unambiguous sentences, they are far from producing gender-inclusive or neutral translations when the gender is unspecified. GPT-4o shows promise, generating appropriate gendered and neutral alternatives for most ambiguous cases, though residual biases remain evident.
WinoWhat: A Parallel Corpus of Paraphrased WinoGrande Sentences with Common Sense Categorization
Mar 31, 2025In this study, we take a closer look at how Winograd schema challenges can be used to evaluate common sense reasoning in LLMs. Specifically, we evaluate generative models of different sizes on the popular WinoGrande benchmark. We release WinoWhat, a new corpus, in which each instance of the WinoGrande validation set is paraphrased. Additionally, we evaluate the performance on the challenge across five common sense knowledge categories, giving more fine-grained insights on what types of knowledge are more challenging for LLMs. Surprisingly, all models perform significantly worse on WinoWhat, implying that LLM reasoning capabilities are overestimated on WinoGrande. To verify whether this is an effect of benchmark memorization, we match benchmark instances to LLM trainingdata and create two test-suites. We observe that memorization has a minimal effect on model performance on WinoGrande.
Joint Emotion Label Space Modelling for Affect Lexica
Nov 20, 2019
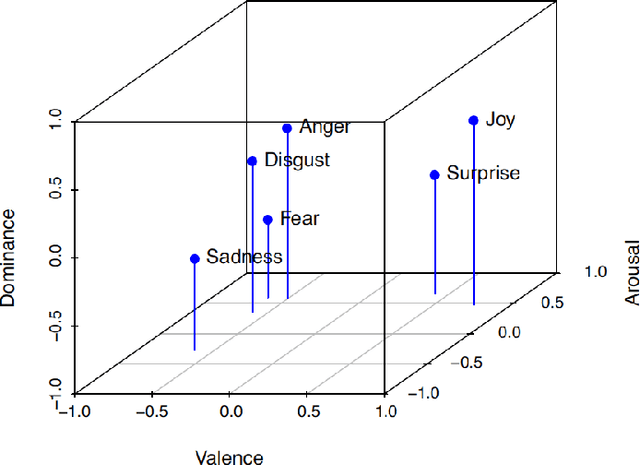
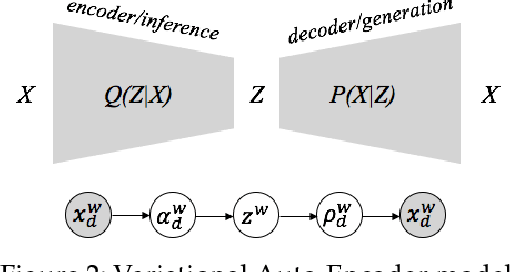

Emotion lexica are commonly used resources to combat data poverty in automatic emotion detection. However, methodological issues emerge when employing them: lexica are often not very extensive, and the way they are constructed can vary widely -- from lab conditions to crowdsourced approaches and distant supervision. Furthermore, both categorical frameworks and dimensional frameworks coexist, in which theorists provide many different sets of categorical labels or dimensional axes. The heterogenous nature of the resulting emotion detection resources results in a need for a unified approach to utilising them. This paper contributes to the field of emotion analysis in NLP by a) presenting the first study to unify existing emotion detection resources automatically and thus learn more about the relationships between them; b) exploring the use of existing lexica for the above-mentioned task; c) presenting an approach to automatically combining emotion lexica, namely by a multi-view variational auto-encoder (VAE), which facilitates the mapping of datasets into a joint emotion label space. We test the utility of joint emotion lexica by using them as additional features in state-of-the art emotion detection models. Our overall findings are that emotion lexica can offer complementary information to even extremely large pre-trained models such as BERT. The performance of our models is comparable to state-of-the art models that are specifically engineered for certain datasets, and even outperform the state-of-the art on four datasets.