 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAspects of Pattern-Matching in Data-Oriented Parsing
Paper and Code
Aug 18, 2000
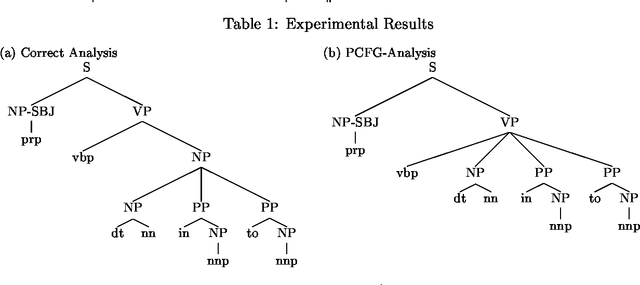
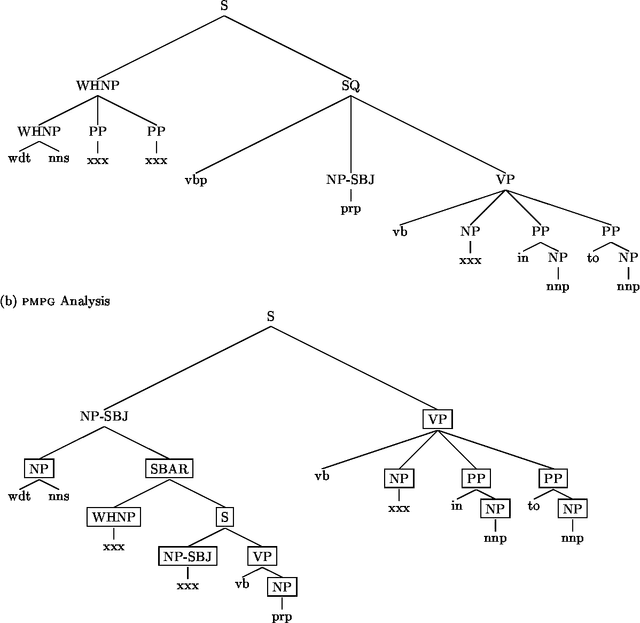
Data-Oriented Parsing (dop) ranks among the best parsing schemes, pairing state-of-the art parsing accuracy to the psycholinguistic insight that larger chunks of syntactic structures are relevant grammatical and probabilistic units. Parsing with the dop-model, however, seems to involve a lot of CPU cycles and a considerable amount of double work, brought on by the concept of multiple derivations, which is necessary for probabilistic processing, but which is not convincingly related to a proper linguistic backbone. It is however possible to re-interpret the dop-model as a pattern-matching model, which tries to maximize the size of the substructures that construct the parse, rather than the probability of the parse. By emphasizing this memory-based aspect of the dop-model, it is possible to do away with multiple derivations, opening up possibilities for efficient Viterbi-style optimizations, while still retaining acceptable parsing accuracy through enhanced context-sensitivity.