 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFranken-Adapter: Cross-Lingual Adaptation of LLMs by Embedding Surgery
Feb 12, 2025The capabilities of Large Language Models (LLMs) in low-resource languages lag far behind those in English, making their universal accessibility a significant challenge. To alleviate this, we present $\textit{Franken-Adapter}$, a modular language adaptation approach for decoder-only LLMs with embedding surgery. Our method begins by creating customized vocabularies for target languages and performing language adaptation through embedding tuning on multilingual data. These pre-trained embeddings are subsequently integrated with LLMs that have been instruction-tuned on English alignment data to enable zero-shot cross-lingual transfer. Our experiments on $\texttt{Gemma2}$ models with up to 27B parameters demonstrate improvements of up to 20% across 96 languages, spanning both discriminative and generative tasks, with minimal regressions ($<$1%) in English. Further in-depth analysis reveals the critical role of customizing tokenizers in enhancing language adaptation, while boosting inference efficiency. Additionally, we show the versatility of our method by achieving a 14% improvement over a math-optimized LLM across 20 languages, offering a modular solution to transfer reasoning abilities across languages post hoc.
Mufu: Multilingual Fused Learning for Low-Resource Translation with LLM
Sep 20, 2024Multilingual large language models (LLMs) are great translators, but this is largely limited to high-resource languages. For many LLMs, translating in and out of low-resource languages remains a challenging task. To maximize data efficiency in this low-resource setting, we introduce Mufu, which includes a selection of automatically generated multilingual candidates and an instruction to correct inaccurate translations in the prompt. Mufu prompts turn a translation task into a postediting one, and seek to harness the LLM's reasoning capability with auxiliary translation candidates, from which the model is required to assess the input quality, align the semantics cross-lingually, copy from relevant inputs and override instances that are incorrect. Our experiments on En-XX translations over the Flores-200 dataset show LLMs finetuned against Mufu-style prompts are robust to poor quality auxiliary translation candidates, achieving performance superior to NLLB 1.3B distilled model in 64% of low- and very-low-resource language pairs. We then distill these models to reduce inference cost, while maintaining on average 3.1 chrF improvement over finetune-only baseline in low-resource translations.
The CARFAC v2 Cochlear Model in Matlab, NumPy, and JAX
Apr 26, 2024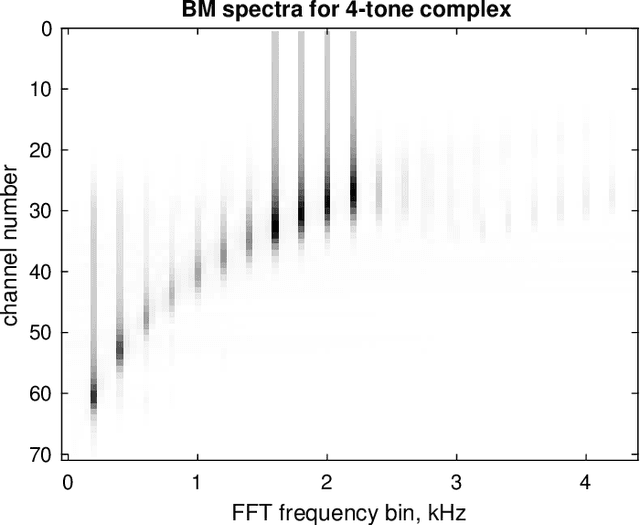

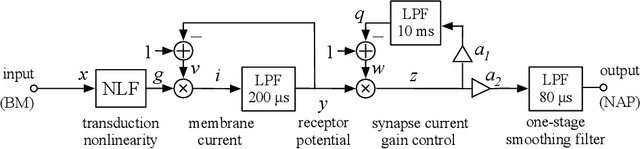
The open-source CARFAC (Cascade of Asymmetric Resonators with Fast-Acting Compression) cochlear model is upgraded to version 2, with improvements to the Matlab implementation, and with new Python/NumPy and JAX implementations -- but C++ version changes are still pending. One change addresses the DC (direct current, or zero frequency) quadratic distortion anomaly previously reported; another reduces the neural synchrony at high frequencies; the others have little or no noticeable effect in the default configuration. A new feature allows modeling a reduction of cochlear amplifier function, as a step toward a differentiable parameterized model of hearing impairment. In addition, the integration into the Auditory Model Toolbox (AMT) has been extensively improved, as the prior integration had bugs that made it unsuitable for including CARFAC in multi-model comparisons.