 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA dataset and model for recognition of audiologically relevant environments for hearing aids: AHEAD-DS and YAMNet+
Aug 14, 2025Scene recognition of audiologically relevant environments is important for hearing aids; however, it is challenging, in part because of the limitations of existing datasets. Datasets often lack public accessibility, completeness, or audiologically relevant labels, hindering systematic comparison of machine learning models. Deploying these models on resource-constrained edge devices presents another challenge. Our solution is two-fold: we leverage several open source datasets to create AHEAD-DS, a dataset designed for scene recognition of audiologically relevant environments, and introduce YAMNet+, a sound recognition model. AHEAD-DS aims to provide a standardised, publicly available dataset with consistent labels relevant to hearing aids, facilitating model comparison. YAMNet+ is designed for deployment on edge devices like smartphones connected to hearing devices, such as hearing aids and wireless earphones with hearing aid functionality; serving as a baseline model for sound-based scene recognition. YAMNet+ achieved a mean average precision of 0.83 and accuracy of 0.93 on the testing set of AHEAD-DS across fourteen categories of audiologically relevant environments. We found that applying transfer learning from the pretrained YAMNet model was essential. We demonstrated real-time sound-based scene recognition capabilities on edge devices by deploying YAMNet+ to an Android smartphone. Even with a Google Pixel 3 (a phone with modest specifications, released in 2018), the model processes audio with approximately 50ms of latency to load the model, and an approximate linear increase of 30ms per 1 second of audio. Our website and code https://github.com/Australian-Future-Hearing-Initiative .
Identifying Hearing Difficulty Moments in Conversational Audio
Jul 31, 2025Individuals regularly experience Hearing Difficulty Moments in everyday conversation. Identifying these moments of hearing difficulty has particular significance in the field of hearing assistive technology where timely interventions are key for realtime hearing assistance. In this paper, we propose and compare machine learning solutions for continuously detecting utterances that identify these specific moments in conversational audio. We show that audio language models, through their multimodal reasoning capabilities, excel at this task, significantly outperforming a simple ASR hotword heuristic and a more conventional fine-tuning approach with Wav2Vec, an audio-only input architecture that is state-of-the-art for automatic speech recognition (ASR).
Multi-Channel Speech Denoising for Machine Ears
Feb 17, 2022
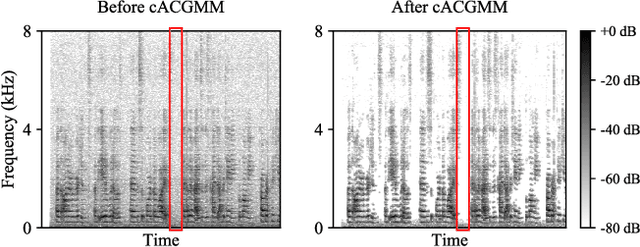


This work describes a speech denoising system for machine ears that aims to improve speech intelligibility and the overall listening experience in noisy environments. We recorded approximately 100 hours of audio data with reverberation and moderate environmental noise using a pair of microphone arrays placed around each of the two ears and then mixed sound recordings to simulate adverse acoustic scenes. Then, we trained a multi-channel speech denoising network (MCSDN) on the mixture of recordings. To improve the training, we employ an unsupervised method, complex angular central Gaussian mixture model (cACGMM), to acquire cleaner speech from noisy recordings to serve as the learning target. We propose a MCSDN-Beamforming-MCSDN framework in the inference stage. The results of the subjective evaluation show that the cACGMM improves the training data, resulting in better noise reduction and user preference, and the entire system improves the intelligibility and listening experience in noisy situations.
Neural Architecture Search for Energy Efficient Always-on Audio Models
Feb 09, 2022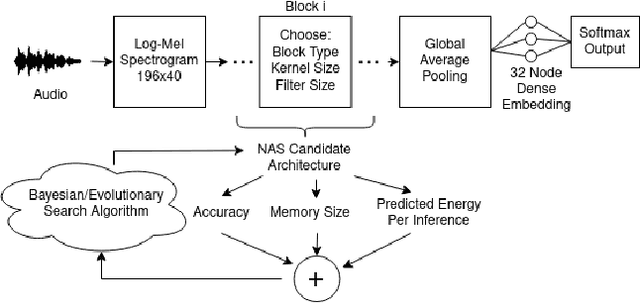
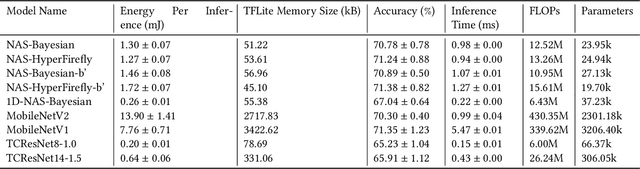
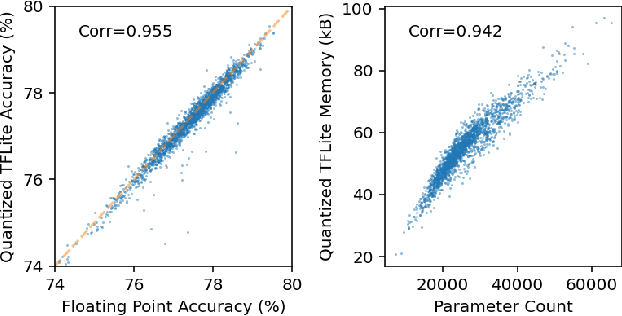
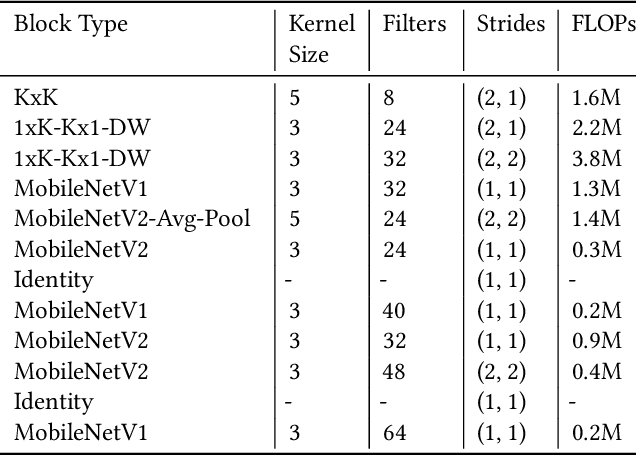
Mobile and edge computing devices for always-on audio classification require energy-efficient neural network architectures. We present a neural architecture search (NAS) that optimizes accuracy, energy efficiency and memory usage. The search is run on Vizier, a black-box optimization service. We present a search strategy that uses both Bayesian and regularized evolutionary search with particle swarms, and employs early-stopping to reduce the computational burden. The search returns architectures for a sound-event classification dataset based upon AudioSet with similar accuracy to MobileNetV1/V2 implementations but with an order of magnitude less energy per inference and a much smaller memory footprint.