 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCroissant: A Metadata Format for ML-Ready Datasets
Mar 28, 2024Data is a critical resource for Machine Learning (ML), yet working with data remains a key friction point. This paper introduces Croissant, a metadata format for datasets that simplifies how data is used by ML tools and frameworks. Croissant makes datasets more discoverable, portable and interoperable, thereby addressing significant challenges in ML data management and responsible AI. Croissant is already supported by several popular dataset repositories, spanning hundreds of thousands of datasets, ready to be loaded into the most popular ML frameworks.
Optimal Stopping via Randomized Neural Networks
Apr 28, 2021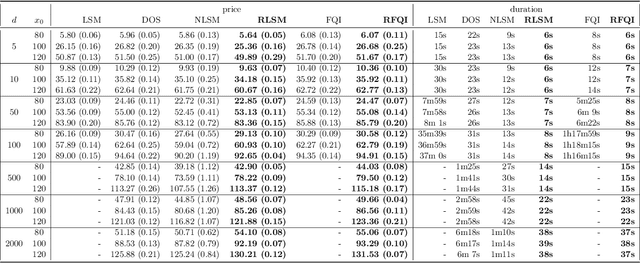
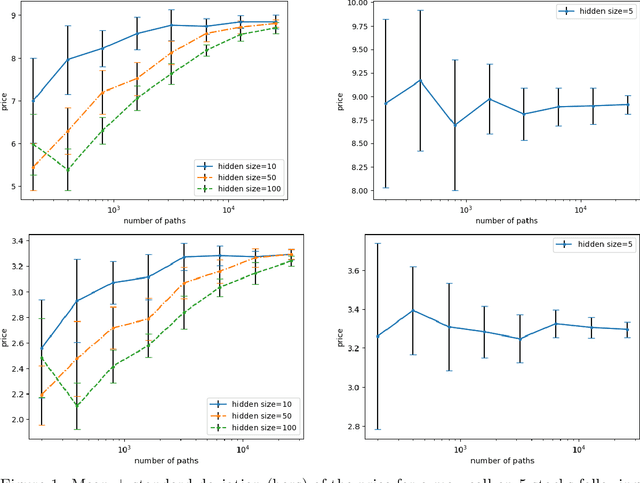

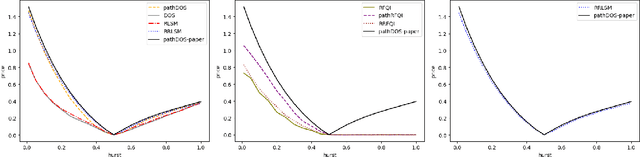
This paper presents new machine learning approaches to approximate the solution of optimal stopping problems. The key idea of these methods is to use neural networks, where the hidden layers are generated randomly and only the last layer is trained, in order to approximate the continuation value. Our approaches are applicable for high dimensional problems where the existing approaches become increasingly impractical. In addition, since our approaches can be optimized using a simple linear regression, they are very easy to implement and theoretical guarantees can be provided. In Markovian examples our randomized reinforcement learning approach and in non-Markovian examples our randomized recurrent neural network approach outperform the state-of-the-art and other relevant machine learning approaches.
The Visual Task Adaptation Benchmark
Oct 01, 2019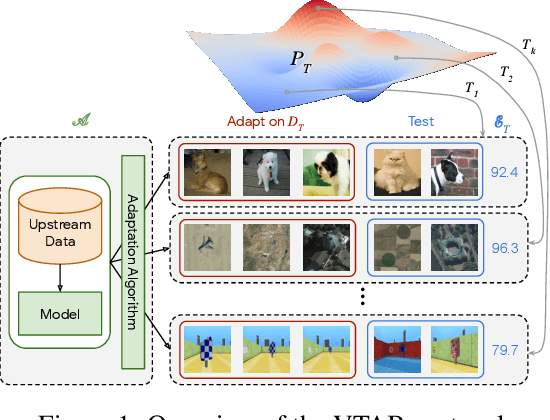
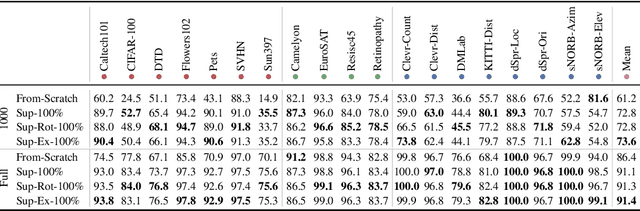
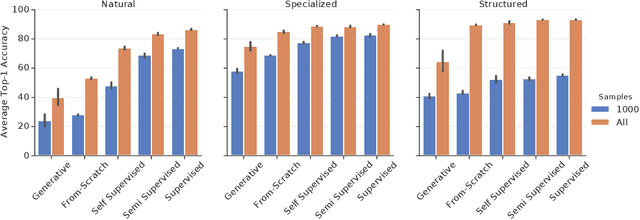
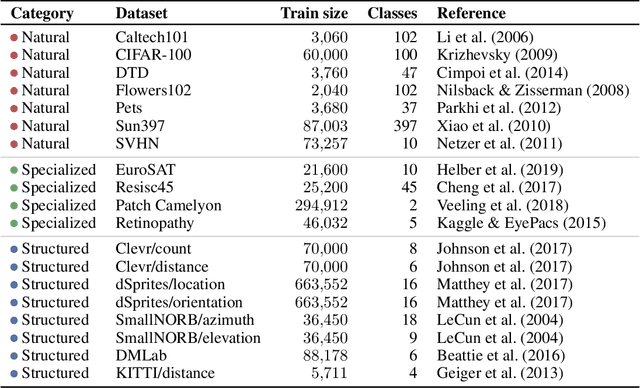
Representation learning promises to unlock deep learning for the long tail of vision tasks without expansive labelled datasets. Yet, the absence of a unified yardstick to evaluate general visual representations hinders progress. Many sub-fields promise representations, but each has different evaluation protocols that are either too constrained (linear classification), limited in scope (ImageNet, CIFAR, Pascal-VOC), or only loosely related to representation quality (generation). We present the Visual Task Adaptation Benchmark (VTAB): a diverse, realistic, and challenging benchmark to evaluate representations. VTAB embodies one principle: good representations adapt to unseen tasks with few examples. We run a large VTAB study of popular algorithms, answering questions like: How effective are ImageNet representation on non-standard datasets? Are generative models competitive? Is self-supervision useful if one already has labels?