 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeLO: Training Versatile Learned Optimizers by Scaling Up
Nov 17, 2022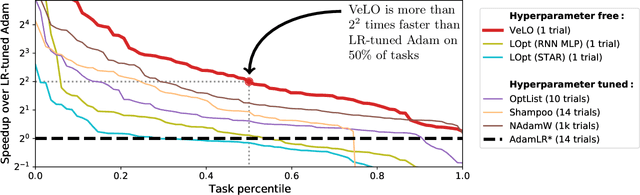
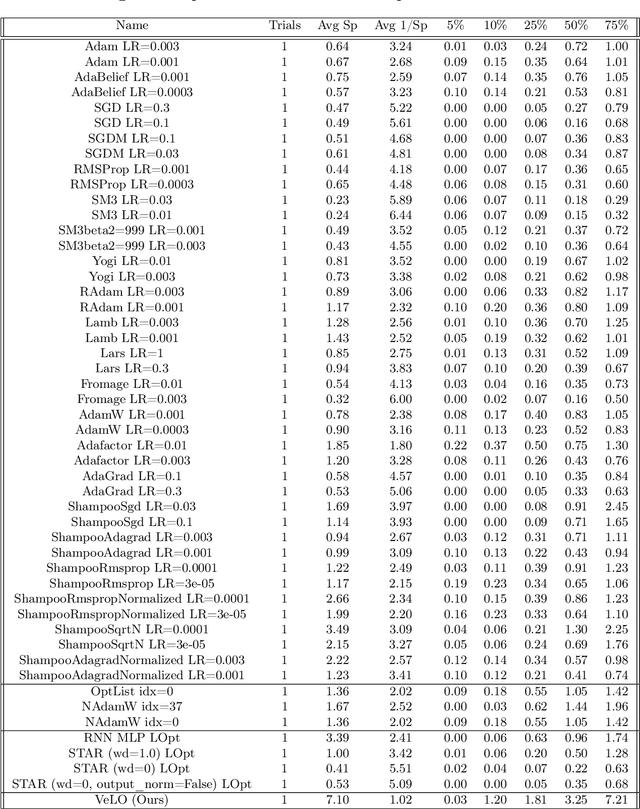
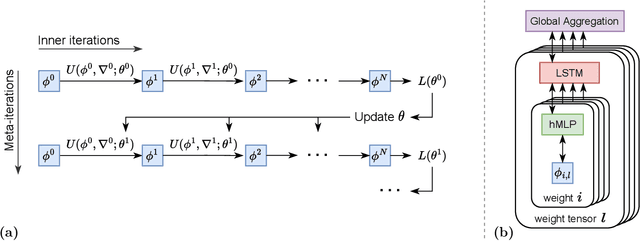
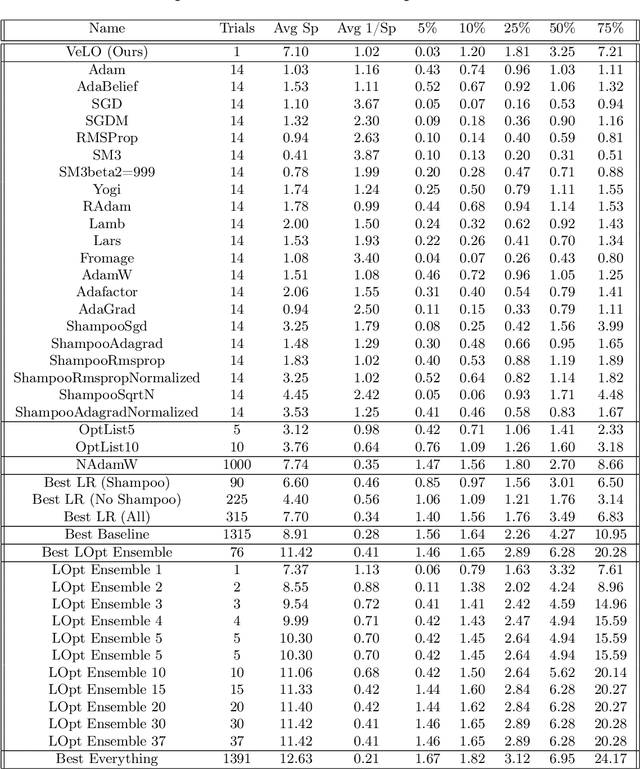
While deep learning models have replaced hand-designed features across many domains, these models are still trained with hand-designed optimizers. In this work, we leverage the same scaling approach behind the success of deep learning to learn versatile optimizers. We train an optimizer for deep learning which is itself a small neural network that ingests gradients and outputs parameter updates. Meta-trained with approximately four thousand TPU-months of compute on a wide variety of optimization tasks, our optimizer not only exhibits compelling performance, but optimizes in interesting and unexpected ways. It requires no hyperparameter tuning, instead automatically adapting to the specifics of the problem being optimized. We open source our learned optimizer, meta-training code, the associated train and test data, and an extensive optimizer benchmark suite with baselines at velo-code.github.io.